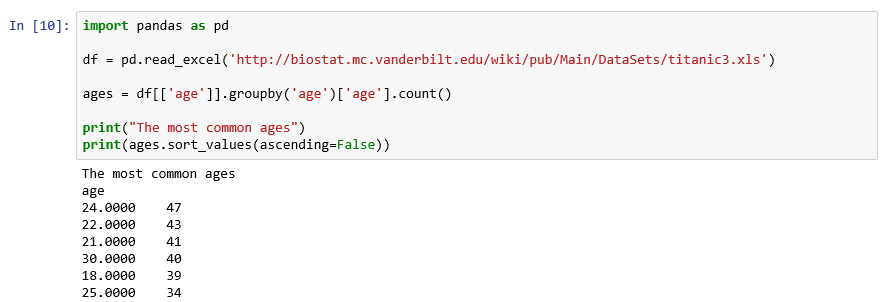
An interesting column manipulation is to sort. We can sort the prior age count data to determine the most common ages for travelers on the boat using the sort_values function.
The script is as follows:
import pandas as pd
df = pd.read_excel('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls')
# the [[]] syntax extracts the column(s) into a new dataframe
# we groupby the age column, and
# apply a count to the age column
ages = df[['age']].groupby('age')['age'].count()
print("The most common ages")
print (ages.sort_values(ascending=False))
The resultant Jupyter display is as follows. From the data, there were many younger travelers on board. In light of this, it makes more sense why there were so many babies as well.