
7.8. Pharmacokinetic Models with Multiple Measurements per Patient
In this section we discuss a clinical pharmacokinetic (PK) study where multiple blood samples are taken for each enrolled patient. This setup leads to nonlinear mixed effects regression models with multiple responses.
7.8.1. Two-Compartment Pharmacokinetic Model
Consider a clinical trial in which the drug was administered as a bolus input D0 at the beginning of the study (at time x = 0) and then bolus inputs Di were administered at 12 or 24 hour intervals until 72 hours after the first dose. To describe the concentration of drug at time x, a two-compartment model was used with standard parameterization (volume of distribution V, transfer rate constants K12, K21 and K10), see Figure 7.14.
Figure 7-13. Left panel: Initial (open circles) and optimal (closed circles) designs. Right panel: Sensitivity functions for the initial (dashed curve) and optimal (solid curve) designs.
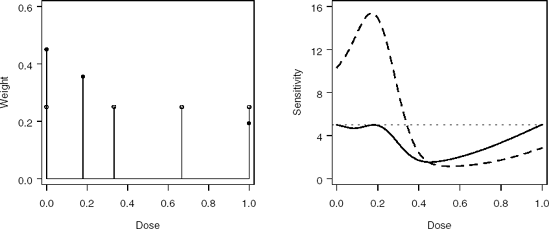
Figure 7-14. Diagram of the two-compartment model

Measurements of drug concentration yij were taken from the central compartment (compartment 1 in Fig. 7.14) at times xj for each patient,
g1(xj) = g1(xj,γi) is the amount of the drug in the central compartment at time xj for patient i, γi = (Vi,K12,i,K21,i,K10,i) are individual PK parameters of patient i and zij are measurement errors. The g1 function and population model are discussed in more detail below.
In the trial under consideration k = 16 samples were taken from each patient at times xj ∈ χ,
Obviously, each extra sample provides additional information and increases the precision of parameter estimates. However, the number of samples that may be drawn from each patient is restricted because of blood volume limitations and other logistical and ethical reasons. Moreover, the analysis of each sample is associated with monetary costs. Therefore, it is reasonable to take the cost of drawing samples into account. If X = (x1,..., xk) is a collection of sampling times for a particular patient, we can consider the cost of the sampling sequence X (denoted by c(X)).
In this section we will consider the following questions:
Given restrictions on the number of samples for each patient, what are the optimal sampling times (i.e., how many samples and at which times)?
If not all 16 samples are taken, what would be the loss of information/precision?
If costs are taken into account, what is the optimal sampling scheme? Cost-based designs will be discussed in detail in Section 7.9.
By an optimal sampling scheme we mean a sequence which allows us to obtain the best precision of parameter estimates in terms of their variance-covariance matrix and the selected optimality criterion. First, we need to define the regression model with multiple responses, see (7.11). In this and next sections, X will denote a k-dimensional vector of sampling times and Y will be a k-dimensional vector of measurements at times X.
7.8.2. Regression Model
A two-compartment model described by the following system of linear differential equations was used to model the data:
for x ∈ [ti,ti+1) with initial conditions
where q1(x) and q2(x) are amounts of the drug at time x in the central and peripheral compartments, respectively; ti is a time of i-th bolus input, t0 = 0; Di is the amount of the drug administered at ti.
The solution of the system (7.19) is a sum of exponential functions which depend on parameters (Gibaldi and Perrier, 1982, Appendix B):
In population modeling it is often assumed that the γi parameters for patient i are independently sampled from the normal population with
where the mγ-dimensional vector γ0 and (mγ × mγ) matrix Λ are usually referred to as the "population", or "global", parameters; see Gagnon and Leonov (2005) for a discussion on other population distributions.
To fit the model, it was assumed that the variance of the error term zij in (7.18) depends on the model parameters through the mean response,
where ε1,ij and ε2,ij are independent, identically distributed random variables with zero mean and variance σ12 and σ22, respectively.
Let θ = (γ0,Λ, σ12,σ22) denote a combined vector of model parameters and ki denote the number of samples taken for patient i. Let
be sampling times and measured concentrations, respectively, for patient i. Further, η(xji,γi) = q1(xji,γi)/Vi, η(xji,θ) = q1(xji,γ0)/V and
where j = 1,2,...,ki.
If F is a (ki × mγ) matrix of partial derivatives of function η(Xi,θ) with respect to parameters γ0,
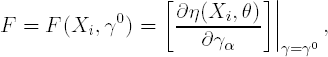
then, using the first order approximation together with (7.20) and (7.21), one obtains the following approximation of the variance-covariance matrix S(Xi,θ) for Yi,
where Diag(A) denotes a diagonal matrix with elements aii on the diagonal; see also Fedorov, Gagnon and Leonov (2002; Section 4). If the γ parameters are assumed to be log-normally distributed, then Λ on the right-hand side of (7.22) has to be replaced with
for details, see Gagnon and Leonov (2005). Therefore, for any sequence Xi, the response vector η(Xi,θ) and variance-covariance matrix S(Xi,θ) are defined, and we can use general formula (7.12) to calculate the information matrix μ(Xi,θ).
7.8.3. Example 9. Pharmacokinetic Model without Cost Constraints
Consider a problem of selecting an optimal sampling scheme with a single bolus input at time x = 0. SAS code for generating optimal designs for the general case of multiple bolus inputs is available (Gagnon and Leonov, 2005), but the complexity of this code is beyond the scope of the chapter.
To fit the data, the K12 and K21 parameters were treated as constants (K12 = 0.400, K21 = 0.345), i.e., they were not accounted for while calculating the information matrix μ(x,θ). Therefore, the combined vector of unknown parameters θ was defined as
where
CL is the plasma clearance and K10 = CL/V. The total number of unknown parameters is m = 7.
To construct locally optimal designs, we obtained the parameter estimates ![]() using the NONMEM software (Beal and Sheiner, 1992) based on 16 samples (from the design region χ) for each of 27 subjects. The resulting estimate is given by
using the NONMEM software (Beal and Sheiner, 1992) based on 16 samples (from the design region χ) for each of 27 subjects. The resulting estimate is given by
Drug concentrations were expressed in μg/L, elimination rate constant K10 in L/h and volume V in L.
The PK modeling problem considered in this section greatly increases the complexity of the SAS implementation of D-optimal designs. Program 7.9 relies on a series of SAS macros and SAS/IML modules to solve the optimal selection problem formulated earlier in this section. Referring back to Section 7.1.7, Components 1, 2 and 3 of the general optimal design algorithm require extensive changes. These changes are summarized below.
In order to generate the grid, the set of sampling times χ is defined in the CAND data set and the number of time points r in the final design is specified in the KS data set (in this case, we are looking for 8-point designs). Note that r ranges between 1 and k, where k is the total number of sampling times (k = 16 in this case). Any number of sets of size r can be applied to the optimization algorithm; however, for designs with the standard information matrix normalization, the design with the largest r will be D-optimal. This will not (necessarily) be true for cost normalized designs (see Section 7.9).
The problem of selecting candidate points is a C(k,r) problem, where C(k,r) is a binomial coefficient, C(k,r) = k!/[r!(k - r)!]. Sets of size r candidate points can become very large. For example, for k = 16 and r = 8, the number of possible 8-point sampling schemes is C(16,8) = 12,870 which means that 12,870 information matrices need to be obtained. Note that in this example m = 7 and thus each information matrix is a 7 × 7 matrix. In order to store the information matrices for all possible 8-point designs, SAS needs to store 12,870 × 7 = 90,090 rows (and 7 columns) of data. Hence the data storage requirements for large designs can become formidable. Once the CAND and KS data sets are specified, Program 7.9 will generate the set of possible candidate points using the SAS/IML module TS. Also, the initial design is specified in the SAMPLE data set (note that all points in the initial design must be elements of the design region χ and must be of length r, as specified in the KS dataset).
The set of parameters has been defined as θ = (γ10,γ20,λ11,λ22,λ12,σ12,σ22).T Since we are dealing with a mixed effects model, the γ and λ parameters in the vector θ must be identified. This is accomplished by ordering the parameters in a specific way. In general, the parameters in θ must be entered as follows: vector γ, vector λ, and residual variance(s). The number of components in γ is defined by the NF macro variable. The ordering of the random effects (the λ's) is also highly important. Parameters along the main diagonal of Λ should be entered first: λ11,λ22. The off-diagonal element (λ12) should be entered next. The Λ matrix is set up using the SAS/IML module LSETUP. In the general case, when Λ is a b × b matrix, the components of Λ need to be ordered as follows: diagonal elements, λ11,λ22,...,λbb, followed by off-diagonal elements λ12,λ13,...,λ1b, λ23,λ24,λ2b,..., etc.
The PK function, η(x,θ), derived from (7.19), is specified using the SAS/IML module FPARA. The ordering of the γ's in the vector of parameters must match the ordering in the FPARA module. As shown in Program 7.9, CL (plasma clearance) should be entered into θ first, and V (volume of distribution) should be entered second. In the current version, the equations in (7.19) must be solved, and the solution must be entered in the FPARA module.
A computationally difficult issue is the calculation of derivatives for (7.12). Note that first- and second-order partial derivatives are required; see equations (7.12), (7.22). In the previous examples derivatives were obtained by either entering the analytical form or by using the NLPFDD function in SAS/IML. Here, we find it more practical to calculate the derivatives numerically using the following approximation

where the value of h is a macro variable and is entered by the user (h = 0.001 in this example). The information matrix from (7.12) is computed via the SAS/IML module MOLD, which calls six other modules (HIGHERD, HIGHERM, FPLUS, FMINUS, FTHETA and JACOB2).
The complete SAS code for this example is provided on the book's companion Web site.
Example 7-9. D-optimal design for the pharmacokinetic model (Design and algorithm parameters)
* Design parameters;
%let h=0.001; * Delta for finite difference derivative approximation;
%let paran=7; * Number of parameters in the model;
%let nf=2; * Number of fixed effect parameters;
%let cost=1; * Cost function (1, no cost function,
2, user-specified function);
* Algorithm parameters;
%let convc=1e-9;
%let maximit=1000;
%let const1=2;
%let const2=1;
%let cmerge=5;
* PK parameters;
data para;
input CL V vCL vV covCLV m s;
datalines;
0.211 5.50 0.0365 0.0949 0.0443 0.0213 8060
;
* All candidate points;
data cand;
input x @@;
datalines;
0.083 0.25 0.5 0.75 1 2 3 4 5 6 12 24 36 48 72 144
;
* Number of time points in the final design;
data ks;
input r @@;
datalines;
8
;
* Initial design;
data sample;
input x1 x2 x3 x4 x5 x6 x7 x8 w @@;
datalines;
0.083 0.5 1 4 12 24 72 144 1.0
;
run; |
Example. Output from Program 7.9
Determinant of the covariance matrix D (initial design)
IDED
0.0000136
Determinant of the covariance matrix D (final design)
DETD
8.4959E-6
Optimal design
COL1 COL2 COL3 COL4 COL5 COL6 COL7 COL8
0.083 0.25 0.5 0.75 36 48 72 144 |
Output 7.9 lists the optimal sampling times included in a D-optimal 8-point design (5 min, 15 min, 30 min, 45 min, 36 h, 48 h, 72 h and 144 h). The optimal design differs from the initial design in that it puts more weight on earlier time points, e.g., the optimal design includes the 15-min and 45-min which were not in the initial design. Note also that an application of the D-optimal algorithm reduced the determinant of the optimal variance-covariance matrix to 8.49 × 10−6 (from 1.36 × 10−5).