
7.9. Models with Cost Constraints
Traditionally, when normalized designs are discussed, the normalization factor is equal to the number of experiments N; see (7.3). In this section we will consider cost-normalized designs. Each measurement at point Xi is assumed to be associated with a cost c(Xi) and a restriction on the total cost is given by
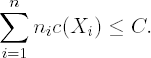
In this case it is quite natural to normalize the information matrix by the total cost C and introduce
Once the cost function c(X) is defined, we can introduce a cost-based design ξC = {wi,Xi and use exactly the same techniques of constructing continuous optimal designs for various optimality criteria as described in the previous sections,
As usual, to obtain counts ni, values ñi = wi C/c(Xi) have to be rounded to the nearest integers ni subject to ∑i nic(Xi) ≤ C.
We believe that the introduction of cost constraints and the alternative normalization (7.23) makes the construction of optimal designs for models with multiple responses more sound. It allows for a meaningful comparison of "points" X with distinct number of responses.
7.9.1. Example 10. Pharmacokinetic Model with Cost Constraints
The example considered in this section is the example discussed in Section 7.8.3 with cost functions added. Program 7.10 computes a D-optimal design by invoking the same SAS macros and SAS/IML modules as Program 7.9. The computational tools for calculating the cost-normalized information matrices are built into the macros and modules, we need only to specify the cost function and set the COST variable to 2 (to indicate that a user-defined cost function will be provided).
The cost function must be entered by the user into the SAS/IML module MCOST. In Program 7.10, we select a linear cost function with two components, the CV variable is associated with an overall cost of the study (i.e., the cost of a patient visit) and CS is the cost of obtaining/analyzing a single sample:
* Cost module;
start mcost(t);
* t is vector sampling times;
Cv = 1;
Cs = 0.3;
C = Cv + sum(Cs[1:nrow(t[loc(t>0)])]);
return(C);
finish(mcost);In general, the cost function can have almost any form.
The design region is defined as follows
that is, we allow any combination of r sampling times for each patient from the original sequence χ, 3 ≤ r ≤ 5. The values of r are specified in the KS data set. Note that the a total of 6,748 information matrices (47,236 rows and 7 columns of data) are calculated and stored in this example.
Example 7-10. D-optimal design for the pharmacokinetic model with cost constraints
* Design parameters;
%let h=0.001; * Delta for finite difference derivative approximation;
%let paran=7; * Number of parameters in the model;
%let nf=2; * Number of fixed effect parameters;
%let cost=2; * Cost function (1, no cost function, 2, user-specified function);
* Algorithm parameters;
%let convc=1e-9;
%let maximit=1000;
%let const1=2;
%let const2=1;
%let cmerge=5;
* PK parameters;
data para;
input CL V vCL vV covCLV m s;
datalines;
0.211 5.50 0.0365 0.0949 0.0443 0.0213 8060
;
* All candidate points;
data cand;
input x @@;
datalines;
0.083 0.25 0.5 0.75 1 2 3 4 5 6 12 24 36 48 72 144;
* Number of time points in the final design;
data ks;
input r @@;
datalines;
3 4 5
;
* Initial design;
data sample;
input x1 x2 x3 x4 x5 w @@;
datalines;
0.083 0.5 4 24 144 1.0
;
run; |
Example. Output from Program 7.10
Determinant of the covariance matrix D (initial design)
IDED
0.231426
Determinant of the covariance matrix D (optimal design)
DETD
0.0209139
Optimal design
Obs COL1 COL2 COL3 COL4 COL5
1 0.083 0.25 48 72 144
2 0.083 0.25 72 144
Optimal weights
Obs W
1 0.59125
2 0.40875 |
Output 7.10 displays the D-optimal design based on the linear cost funtion defined in the MCOST module. The D-optimal design is a collection of two sampling sequences,
with weights w1 = 0.59 and w2 = 0.41, respectively. This example shows that once costs are taken into account, sampling sequences with a smaller number of samples may become optimal.