
When we deal with text documents that contain millions of words, we need to convert them into some kind of numeric representation. The reason for this is to make them usable for machine learning algorithms. These algorithms need numerical data so that they can analyze them and output meaningful information. This is where the bag-of-words approach comes into picture. This is basically a model that learns a vocabulary from all the words in all the documents. After this, it models each document by building a histogram of all the words in the document.
- Create a new Python file, and import the following packages:
import numpy as np from nltk.corpus import brown from chunking import splitter
- Let's define the
mainfunction. Load the input data from the Brown corpus:if __name__=='__main__': # Read the data from the Brown corpus data = ' '.join(brown.words()[:10000]) - Divide the text data into five chunks:
# Number of words in each chunk num_words = 2000 chunks = [] counter = 0 text_chunks = splitter(data, num_words) - Create a dictionary that is based on these text chunks:
for text in text_chunks: chunk = {'index': counter, 'text': text} chunks.append(chunk) counter += 1 - The next step is to extract a document term matrix. This is basically a matrix that counts the number of occurrences of each word in the document. We will use scikit-learn to do this because it has better provisions as compared to NLTK for this particular task. Import the following package:
# Extract document term matrix from sklearn.feature_extraction.text import CountVectorizer - Define the object, and extract the document term matrix:
vectorizer = CountVectorizer(min_df=5, max_df=.95) doc_term_matrix = vectorizer.fit_transform([chunk['text'] for chunk in chunks]) - Extract the vocabulary from the
vectorizerobject and print it:vocab = np.array(vectorizer.get_feature_names()) print " Vocabulary:" print vocab - Print the document term matrix:
print " Document term matrix:" chunk_names = ['Chunk-0', 'Chunk-1', 'Chunk-2', 'Chunk-3', 'Chunk-4'] - To print in tabular form, we need to format this, as follows:
formatted_row = '{:>12}' * (len(chunk_names) + 1) print ' ', formatted_row.format('Word', *chunk_names), ' ' - Iterate through the words, and print the number of times each word has occurred in different chunks:
for word, item in zip(vocab, doc_term_matrix.T): # 'item' is a 'csr_matrix' data structure output = [str(x) for x in item.data] print formatted_row.format(word, *output) - The full code is in the
bag_of_words.pyfile. If you run this code, you will see two main things printed on the Terminal. The first output is the vocabulary as shown in the following image:
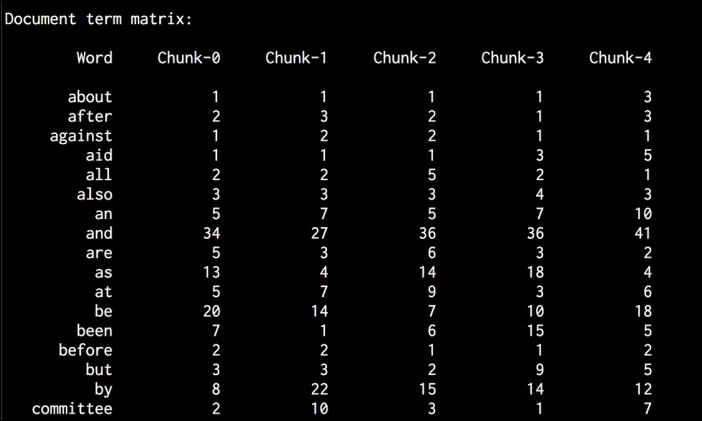
- The second thing is the document term matrix, which is a pretty long. The first few lines will look like the following:
Consider the following sentences:
- Sentence 1: The brown dog is running.
- Sentence 2: The black dog is in the black room.
- Sentence 3: Running in the room is forbidden.
If you consider all the three sentences, we have the following nine unique words:
- the
- brown
- dog
- is
- running
- black
- in
- room
- forbidden
Now, let's convert each sentence into a histogram using the count of words in each sentence. Each feature vector will be 9-dimensional because we have nine unique words:
- Sentence 1: [1, 1, 1, 1, 1, 0, 0, 0, 0]
- Sentence 2: [2, 0, 1, 1, 0, 2, 1, 1, 0]
- Sentence 3: [0, 0, 0, 1, 1, 0, 1, 1, 1]
Once we extract these feature vectors, we can use machine learning algorithms to analyze them.