
6.1 Basic Concepts
Frequent pattern mining searches for recurring relationships in a given data set. This section introduces the basic concepts of frequent pattern mining for the discovery of interesting associations and correlations between itemsets in transactional and relational databases. We begin in Section 6.1.1 by presenting an example of market basket analysis, the earliest form of frequent pattern mining for association rules. The basic concepts of mining frequent patterns and associations are given in Section 6.1.2.
6.1.1 Market Basket Analysis: A Motivating Example
Frequent itemset mining leads to the discovery of associations and correlations among items in large transactional or relational data sets. With massive amounts of data continuously being collected and stored, many industries are becoming interested in mining such patterns from their databases. The discovery of interesting correlation relationships among huge amounts of business transaction records can help in many business decision-making processes such as catalog design, cross-marketing, and customer shopping behavior analysis.
A typical example of frequent itemset mining is market basket analysis. This process analyzes customer buying habits by finding associations between the different items that customers place in their “shopping baskets” (Figure 6.1). The discovery of these associations can help retailers develop marketing strategies by gaining insight into which items are frequently purchased together by customers. For instance, if customers are buying milk, how likely are they to also buy bread (and what kind of bread) on the same trip to the supermarket? This information can lead to increased sales by helping retailers do selective marketing and plan their shelf space.
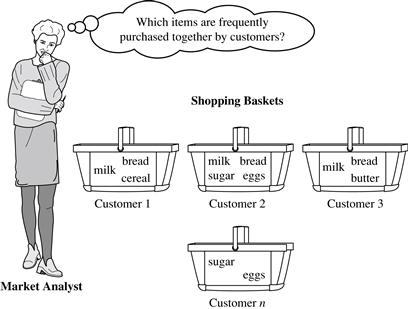
Let’s look at an example of how market basket analysis can be useful.
If we think of the universe as the set of items available at the store, then each item has a Boolean variable representing the presence or absence of that item. Each basket can then be represented by a Boolean vector of values assigned to these variables. The Boolean vectors can be analyzed for buying patterns that reflect items that are frequently associated or purchased together. These patterns can be represented in the form of association rules. For example, the information that customers who purchase computers also tend to buy antivirus software at the same time is represented in the following association rule:
![]() (6.1)
(6.1)
Rule support and confidence are two measures of rule interestingness. They respectively reflect the usefulness and certainty of discovered rules. A support of 2% for Rule (6.1) means that 2% of all the transactions under analysis show that computer and antivirus software are purchased together. A confidence of 60% means that 60% of the customers who purchased a computer also bought the software. Typically, association rules are considered interesting if they satisfy both a minimum support threshold and a minimum confidence threshold. These thresholds can be a set by users or domain experts. Additional analysis can be performed to discover interesting statistical correlations between associated items.
6.1.2 Frequent Itemsets, Closed Itemsets, and Association Rules
Let ![]() be an itemset. Let D, the task-relevant data, be a set of database transactions where each transaction T is a nonempty itemset such that
be an itemset. Let D, the task-relevant data, be a set of database transactions where each transaction T is a nonempty itemset such that ![]() . Each transaction is associated with an identifier, called a TID. Let A be a set of items. A transaction T is said to contain A if
. Each transaction is associated with an identifier, called a TID. Let A be a set of items. A transaction T is said to contain A if ![]() . An association rule is an implication of the form
. An association rule is an implication of the form ![]() , where
, where ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() . The rule
. The rule ![]() holds in the transaction set D with support s, where s is the percentage of transactions in D that contain
holds in the transaction set D with support s, where s is the percentage of transactions in D that contain ![]() (i.e., the union of sets A and B say, or, both A and B). This is taken to be the probability,
(i.e., the union of sets A and B say, or, both A and B). This is taken to be the probability, ![]() .1 The rule
.1 The rule ![]() has confidence c in the transaction set D, where c is the percentage of transactions in D containing A that also contain B. This is taken to be the conditional probability,
has confidence c in the transaction set D, where c is the percentage of transactions in D containing A that also contain B. This is taken to be the conditional probability, ![]() . That is,
. That is,
![]() (6.2)
(6.2)
![]() (6.3)
(6.3)
Rules that satisfy both a minimum support threshold (min_sup) and a minimum confidence threshold (min_conf) are called strong. By convention, we write support and confidence values so as to occur between 0% and 100%, rather than 0 to 1.0.
A set of items is referred to as an itemset.2 An itemset that contains k items is a k-itemset. The set {computer, antivirus_software } is a 2-itemset. The occurrence frequency of an itemset is the number of transactions that contain the itemset. This is also known, simply, as the frequency, support count, or count of the itemset. Note that the itemset support defined in Eq. (6.2) is sometimes referred to as relative support, whereas the occurrence frequency is called the absolute support. If the relative support of an itemset I satisfies a prespecified minimum support threshold (i.e., the absolute support of I satisfies the corresponding minimum support count threshold), then I is a frequent itemset.3 The set of frequent k-itemsets is commonly denoted by Lk.4
From Eq. (6.3), we have
![]() (6.4)
(6.4)
Equation (6.4) shows that the confidence of rule ![]() can be easily derived from the support counts of A and
can be easily derived from the support counts of A and ![]() . That is, once the support counts of A, B, and
. That is, once the support counts of A, B, and ![]() are found, it is straightforward to derive the corresponding association rules
are found, it is straightforward to derive the corresponding association rules ![]() and
and ![]() and check whether they are strong. Thus, the problem of mining association rules can be reduced to that of mining frequent itemsets.
and check whether they are strong. Thus, the problem of mining association rules can be reduced to that of mining frequent itemsets.
In general, association rule mining can be viewed as a two-step process:
1. Find all frequent itemsets: By definition, each of these itemsets will occur at least as frequently as a predetermined minimum support count, min_sup.
2. Generate strong association rules from the frequent itemsets: By definition, these rules must satisfy minimum support and minimum confidence.
Additional interestingness measures can be applied for the discovery of correlation relationships between associated items, as will be discussed in Section 6.3. Because the second step is much less costly than the first, the overall performance of mining association rules is determined by the first step.
A major challenge in mining frequent itemsets from a large data set is the fact that such mining often generates a huge number of itemsets satisfying the minimum support (min_sup) threshold, especially when min_sup is set low. This is because if an itemset is frequent, each of its subsets is frequent as well. A long itemset will contain a combinatorial number of shorter, frequent sub-itemsets. For example, a frequent itemset of length 100, such as {![]() }, contains
}, contains ![]() frequent 1-itemsets:
frequent 1-itemsets: ![]() ,
, ![]() , …,
, …, ![]() ;
; ![]() frequent 2-itemsets:
frequent 2-itemsets: ![]() ,
, ![]() ,…,
,…,![]() ; and so on. The total number of frequent itemsets that it contains is thus
; and so on. The total number of frequent itemsets that it contains is thus
![]() (6.5)
(6.5)
This is too huge a number of itemsets for any computer to compute or store. To overcome this difficulty, we introduce the concepts of closed frequent itemset and maximal frequent itemset.
An itemset X is closed in a data set D if there exists no proper super-itemset Y5 such that Y has the same support count as X in D. An itemset X is a closed frequent itemset in set D if X is both closed and frequent in D. An itemset X is a maximal frequent itemset (or max-itemset) in a data set D if X is frequent, and there exists no super-itemset Y such that ![]() and Y is frequent in D.
and Y is frequent in D.
Let ![]() be the set of closed frequent itemsets for a data set D satisfying a minimum support threshold,
be the set of closed frequent itemsets for a data set D satisfying a minimum support threshold, ![]() . Let
. Let ![]() be the set of maximal frequent itemsets for D satisfying
be the set of maximal frequent itemsets for D satisfying ![]() . Suppose that we have the support count of each itemset in
. Suppose that we have the support count of each itemset in ![]() and
and ![]() . Notice that
. Notice that ![]() and its count information can be used to derive the whole set of frequent itemsets. Thus, we say that
and its count information can be used to derive the whole set of frequent itemsets. Thus, we say that ![]() contains complete information regarding its corresponding frequent itemsets. On the other hand,
contains complete information regarding its corresponding frequent itemsets. On the other hand, ![]() registers only the support of the maximal itemsets. It usually does not contain the complete support information regarding its corresponding frequent itemsets. We illustrate these concepts with Example 6.2.
registers only the support of the maximal itemsets. It usually does not contain the complete support information regarding its corresponding frequent itemsets. We illustrate these concepts with Example 6.2.
Example 6.2
Closed and maximal frequent itemsets
Suppose that a transaction database has only two transactions: {![]() ;
; ![]() }. Let the minimum support count threshold be
}. Let the minimum support count threshold be ![]() . We find two closed frequent itemsets and their support counts, that is,
. We find two closed frequent itemsets and their support counts, that is, ![]() {{
{{![]() ; {
; {![]() }. There is only one maximal frequent itemset:
}. There is only one maximal frequent itemset: ![]() {{
{{![]() }. Notice that we cannot include {
}. Notice that we cannot include {![]() } as a maximal frequent itemset because it has a frequent superset, {
} as a maximal frequent itemset because it has a frequent superset, {![]() }. Compare this to the preceding where we determined that there are
}. Compare this to the preceding where we determined that there are ![]() frequent itemsets, which are too many to be enumerated!
frequent itemsets, which are too many to be enumerated!
The set of closed frequent itemsets contains complete information regarding the frequent itemsets. For example, from ![]() , we can derive, say, (1) {
, we can derive, say, (1) {![]() } since {
} since {![]() } is a sub-itemset of the itemset {
} is a sub-itemset of the itemset {![]() }; and (2) {
}; and (2) {![]() } since {
} since {![]() } is not a sub-itemset of the previous itemset but of the itemset {
} is not a sub-itemset of the previous itemset but of the itemset {![]() }. However, from the maximal frequent itemset, we can only assert that both itemsets ({
}. However, from the maximal frequent itemset, we can only assert that both itemsets ({![]() } and {
} and {![]() }) are frequent, but we cannot assert their actual support counts.
}) are frequent, but we cannot assert their actual support counts.