
7.8 Exercises
7.1 Propose and outline a level-shared mining approach to mining multilevel association rules in which each item is encoded by its level position. Design it so that an initial scan of the database collects the count for each item at each concept level, identifying frequent and subfrequent items. Comment on the processing cost of mining multilevel associations with this method in comparison to mining single-level associations.
7.2 Suppose, as manager of a chain of stores, you would like to use sales transactional data to analyze the effectiveness of your store’s advertisements. In particular, you would like to study how specific factors influence the effectiveness of advertisements that announce a particular category of items on sale. The factors to study are the region in which customers live and the day-of-the-week and time-of-the-day of the ads. Discuss how to design an efficient method to mine the transaction data sets and explain how multidimensional and multilevel mining methods can help you derive a good solution.
7.3 Quantitative association rules may disclose exceptional behaviors within a data set, where “exceptional” can be defined based on statistical theory. For example, Section 7.2.3 shows the association rule
![]()
which suggests an exceptional pattern. The rule states that the average wage for females is only $7.90 per hour, which is a significantly lower wage than the overall average of $9.02 per hour. Discuss how such quantitative rules can be discovered systematically and efficiently in large data sets with quantitative attributes.
7.4 In multidimensional data analysis, it is interesting to extract pairs of similar cell characteristics associated with substantial changes in measure in a data cube, where cells are considered similar if they are related by roll-up (i.e, ancestors), drill-down (i.e, descendants), or 1-D mutation (i.e, siblings) operations. Such an analysis is called cube gradient analysis.
Suppose the measure of the cube is average. A user poses a set of probe cells and would like to find their corresponding sets of gradient cells, each of which satisfies a certain gradient threshold. For example, find the set of corresponding gradient cells that have an average sale price greater than 20% of that of the given probe cells. Develop an algorithm than mines the set of constrained gradient cells efficiently in a large data cube.
7.5 Section 7.2.4 presented various ways of defining negatively correlated patterns. Consider Definition 7.3: “Suppose that itemsets X and Y are both frequent, that is, ![]() and
and ![]() , where min_sup is the minimum support threshold. If
, where min_sup is the minimum support threshold. If ![]() , where
, where ![]() is a negative pattern threshold, then pattern X ∪ Y is a negatively correlated pattern.” Design an efficient pattern growth algorithm for mining the set of negatively correlated patterns.
is a negative pattern threshold, then pattern X ∪ Y is a negatively correlated pattern.” Design an efficient pattern growth algorithm for mining the set of negatively correlated patterns.
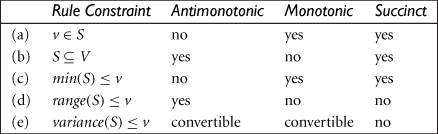
7.6 Prove that each entry in the following table correctly characterizes its corresponding rule constraint for frequent itemset mining.
7.7 The price of each item in a store is non-negative. The store manager is only interested in rules of certain forms, using the constraints given in (a)–(b). For each of the following cases, identify the kinds of constraints they represent and briefly discuss how to mine such association rules using constraint-based pattern mining.
(a) Containing at least one Blu-ray DVD movie.
(b) Containing items with a sum of the prices that is less than $150.
(c) Containing one free item and other items with a sum of the prices that is at least $200.
(d) Where the average price of all the items is between $100 and $500.
7.8 Section 7.4.1 introduced a core Pattern-Fusion method for mining high-dimensional data. Explain why a long pattern, if one exists in the data set, is likely to be discovered by this method.
7.9 Section 7.5.1 defined a pattern distance measure between closed patterns P1 and P2 as
![]()
where T(P1) and T(P2) are the supporting transaction sets of P1 and P2, respectively. Is this a valid distance metric? Show the derivation to support your answer.
7.10 Association rule mining often generates a large number of rules, many of which may be similar, thus not containing much novel information. Design an efficient algorithm that compresses a large set of patterns into a small compact set. Discuss whether your mining method is robust under different pattern similarity definitions.
7.11 Frequent pattern mining may generate many superfluous patterns. Therefore, it is important to develop methods that mine compressed patterns. Suppose a user would like to obtain only k patterns (where k is a small integer). Outline an efficient method that generates the k most representative patterns, where more distinct patterns are preferred over very similar patterns. Illustrate the effectiveness of your method using a small data set.
7.12 It is interesting to generate semantic annotations for mined patterns. Section 7.6.1 presented a pattern annotation method. Alternative methods are possible, such as by utilizing type information. In the DBLP data set, for example, authors, conferences, terms, and papers form multi-typed data. Develop a method for automated semantic pattern annotation that makes good use of typed information.