
HDFS is a software-based filesystem implemented in Java and sits on top of the native file system. The main concept behind HDFS is that it divides a file into blocks (typically 128 MB) instead of dealing with a file as a whole. This allowed many features such as distribution, replication, failure recovery, and more importantly distributed processing of the blocks using multiple machines.
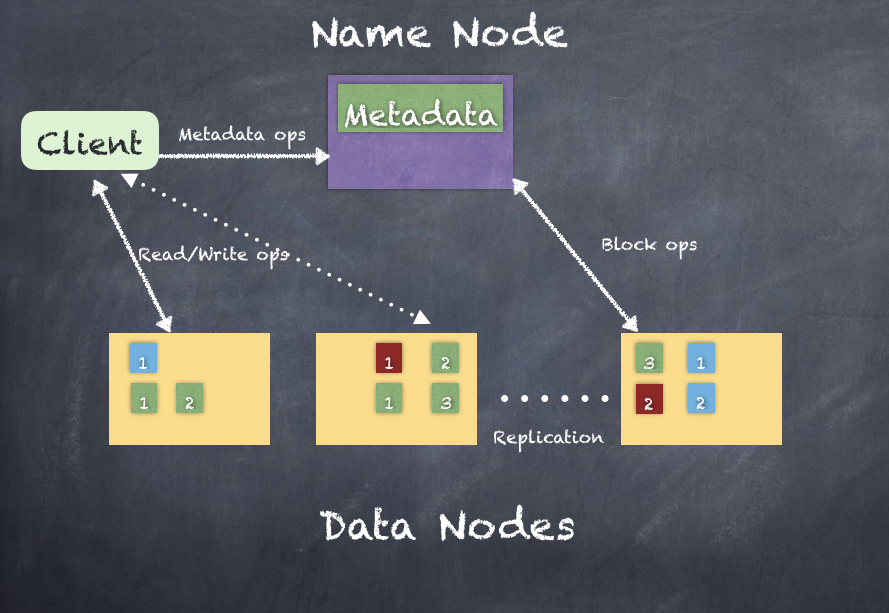
HDFS provides a distributed storage system with fault tolerance and failure recovery. HDFS has two main components: name node and data node(s). Name node contains all the metadata of all content of the file system. Data nodes connect to the Name Node and rely on the name node for all metadata information regarding the content in the file system. If the name node does not know any information, data node will not be able to serve it to any client who wants to read/write to the HDFS.
The following is the HDFS architecture:
NameNode and DataNode are JVM processes so any machine that supports Java can run the NameNode or the DataNode process. There is only one NameNode (the second NameNode will be there too if you count the HA deployment) but 100s if not 1000s of DataNodes.
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata and any client, that wants to read/write data first contacts the NameNode for the metadata information. The data never flows directly through the NameNode, which allows 100s of DataNodes (PBs of data) to be managed by 1 NameNode.
HDFS supports a traditional hierarchical file organization with directories and files similar to most other filesystems. You can create, move, and delete files, and directories. The NameNode maintains the filesystem namespace and records all changes and the state of the filesystem. An application can specify the number of replicas of a file that should be maintained by HDFS and this information is also stored by the NameNode.
HDFS is designed to reliably store very large files in a distributed manner across machines in a large cluster of data nodes. To deal with replication, fault tolerance, as well as distributed computing, HDFS stores each file as a sequence of blocks.
The NameNode makes all decisions regarding the replication of blocks. This is mainly dependent on a Block report from each of the DataNodes in the cluster received periodically at a heart beat interval. A block report contains a list of all blocks on a DataNode, which the NameNode then stores in its metadata repository.
The NameNode stores all metadata in memory and serves all requests from clients reading from/writing to HDFS. However, since this is the master node maintaining all the metadata about the HDFS, it is critical to maintain consistent and reliable metadata information. If this information is lost, the content on the HDFS cannot be accessed.
For this purpose, HDFS NameNode uses a transaction log called the EditLog, which persistently records every change that occurs to the metadata of the filesystem. Creating a new file updates EditLog, so does moving a file or renaming a file, or deleting a file. The entire filesystem namespace, including the mapping of blocks to files and filesystem properties, is stored in a file called the FsImage. The NameNode keeps everything in memory as well. When a NameNode starts up, it loads the EditLog and the FsImage initializes itself to set up the HDFS.
The DataNodes, however, have no idea about the HDFS, purely relying on the blocks of data stored. DataNodes rely entirely on the NameNode to perform any operations. Even when a client wants to connect to read a file or write to a file, it's the NameNode that tells the client where to connect to.