
Once a Spark application is bundled as either a jar file (written in Scala or Java) or a Python file, it can be submitted using the Spark-submit script located under the bin directory in Spark distribution (aka $SPARK_HOME/bin). According to the API documentation provided in Spark website (http://spark.apache.org/docs/latest/submitting-applications.html), the script takes care of the following:
- Setting up the classpath of JAVA_HOME, SCALA_HOME with Spark
- Setting up the all the dependencies required to execute the jobs
- Managing different cluster managers
- Finally, deploying models that Spark supports
In a nutshell, Spark job submission syntax is as follows:
$ spark-submit [options] <app-jar | python-file> [app arguments]
Here, [options] can be: --conf <configuration_parameters> --class <main-class> --master <master-url> --deploy-mode <deploy-mode> ... # other options
- <main-class> is the name of the main class name. This is practically the entry point for our Spark application.
- --conf signifies all the used Spark parameters and configuration property. The format of a configuration property is a key=value format.
- <master-url> specifies the master URL for the cluster (for example, spark://HOST_NAME:PORT) for connecting to the master of the Spark standalone cluster, local for running your Spark jobs locally. By default, it allows you using only one worker thread with no parallelism. The local [k] can be used for running your Spark job locally with K worker threads. It is to be noted that K is the number of cores on your machine. Finally, if you specify the master with local[*] for running Spark job locally, you are giving the permission to the spark-submit script to utilize all the worker threads (logical cores) on your machine have. Finally, you can specify the master as mesos://IP_ADDRESS:PORT for connecting to the available Mesos cluster. Alternatively, you could specify using yarn to run your Spark jobs on a YARN-based cluster.
For other options on Master URL, please refer to the following figure:
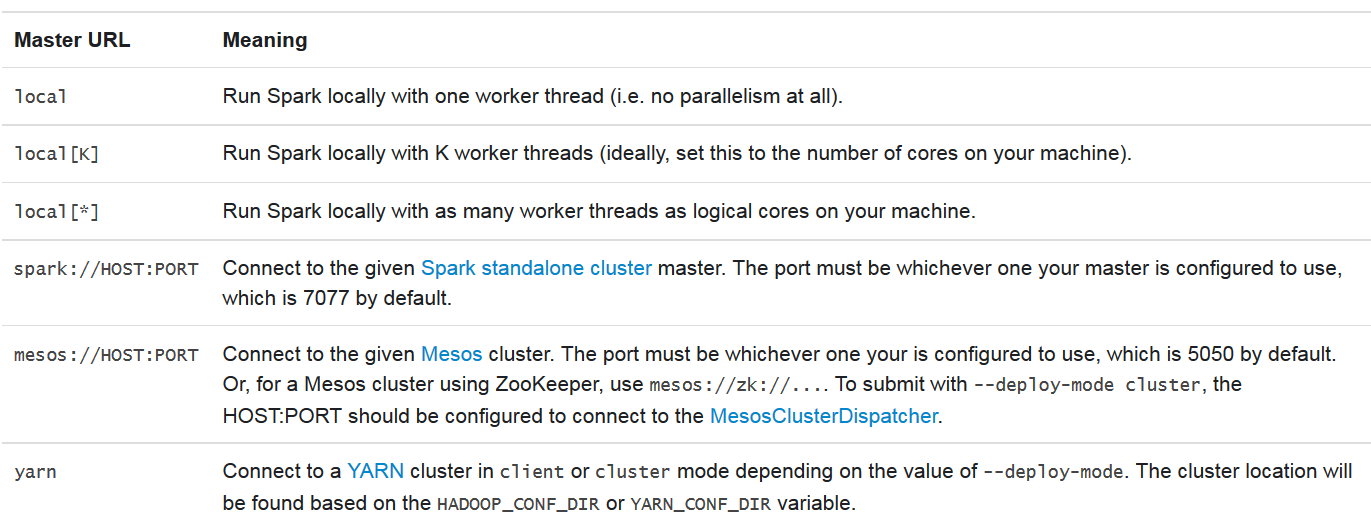
- <deploy-mode> you have to specify this if you want to deploy your driver on the worker nodes (cluster) or locally as an external client (client). Four (4) modes are supported: local, standalone, YARN, and Mesos.
- <app-jar> is the JAR file you build with with dependencies. Just pass the JAR file while submitting your jobs.
- <python-file> is the application main source code written using Python. Just pass the .py file while submitting your jobs.
- [app-arguments] could be input or output argument specified by an application developer.
While submitting the Spark jobs using the spark-submit script, you can specify the main jar of the Spark application (and other related JARS included) using the --jars option. All the JARS will then be transferred to the cluster. URLs supplied after --jars must be separated by commas.
However, if you specify the jar using the URLs, it is a good practice to separate the JARS using commas after --jars. Spark uses the following URL scheme to allow different strategies for disseminating JARS:
- file: Specifies the absolute paths and file:/
- hdfs:, http:, https:, ftp: JARS or any other files will be pull-down from the URLs/URIs you specified as expected
- local: A URI starting with local:/ can be used to point local jar files on each computing node
It is to be noted that dependent JARs, R codes, Python scripts, or any other associated data files need to be copied or replicated to the working directory for each SparkContext on the computing nodes. This sometimes creates a significant overhead and needs a pretty large amount of disk space. The disk usages increase over time. Therefore, at a certain period of time, unused data objects or associated code files need to be cleaned up. This is, however, quite easy with YARN. YARN handles the cleanup periodically and can be handled automatically. For example, with the Spark standalone mode, automatic cleanup can be configured with the spark.worker.cleanup.appDataTtl property while submitting the Spark jobs.
Computationally, the Spark is designed such that during the job submission (using spark-submit script), default Spark config values can be loaded and propagate to Spark applications from a property file. Master node will read the specified options from the configuration file named spark-default.conf. The exact path is SPARK_HOME/conf/spark-defaults.conf in your Spark distribution directory. However, if you specify all the parameters in the command line, this will get higher priority and will be used accordingly.