
MapReduce (MR) framework enables you to write distributed applications to process large amounts of data from a filesystem such as HDFS in a reliable and fault-tolerant manner. When you want to use the MapReduce Framework to process data, it works through the creation of a job, which then runs on the framework to perform the tasks needed.
A MapReduce job usually works by splitting the input data across worker nodes running Mapper tasks in a parallel manner. At this time, any failures that happen either at the HDFS level or the failure of a Mapper task are handled automatically to be fault-tolerant. Once the Mappers are completed, the results are copied over the network to other machines running Reducer tasks.
An easy way to understand this concept is to imagine that you and your friends want to sort out piles of fruit into boxes. For that, you want to assign each person the task of going through one raw basket of fruit (all mixed up) and separate out the fruit into various boxes. Each person then does the same with this basket of fruit.
In the end, you end up with a lot of boxes of fruit from all your friends. Then, you can assign a group to put the same kind of fruit together in a box, weight the box, and seal the box for shipping.
The following depicts the idea of taking fruit baskets and sorting the fruit by the type of fruit:

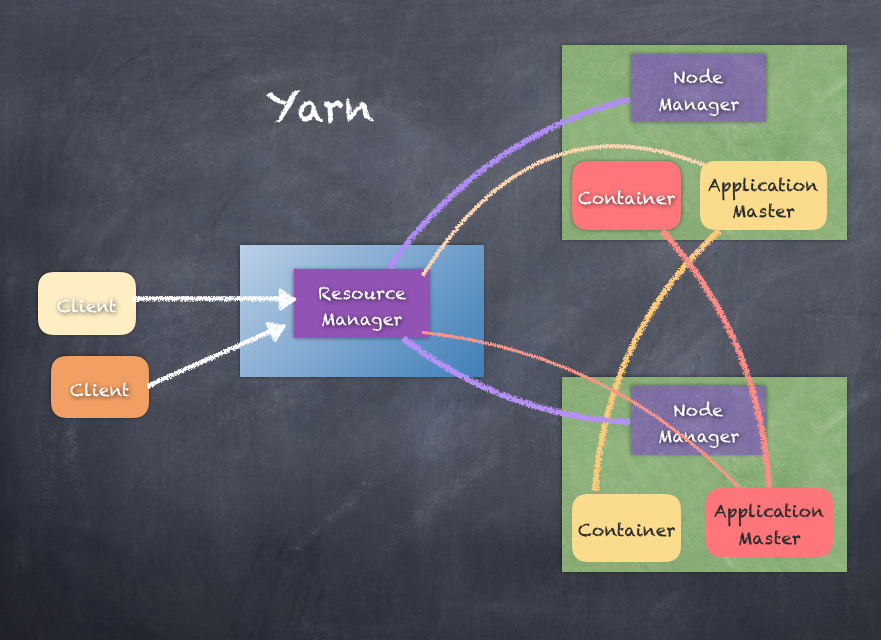
MapReduce framework consists of a single resource manager and multiple node managers (usually Node Managers coexist with the data nodes of HDFS). When an application wants to run, the client launches the application master, which then negotiates with the resource manager to get resources in the cluster in form of containers.
Examples of containers:
1 core + 4 GB RAM
2 cores + 6 GB RAM
4 cores + 20 GB RAM
Some Containers are assigned to be Mappers and other to be Reducers; all this is coordinated by the application master in conjunction with the resource manager. This framework is called Yet Another Resource Negotiator (YARN)
The following is a depiction of YARN:
A classic example showing the MapReduce framework at work is the word count example. The following are the various stages of processing the input data, first splitting the input across multiple worker nodes and then finally generating the output counts of words:

Though MapReduce framework is very successful all across the world and has been adopted by most companies, it does run into issues mainly because of the way it processes data. Several technologies have come into existence to try and make MapReduce easier to use such as Hive and Pig but the complexity remains.
Hadoop MapReduce has several limitations such as:
- Performance bottlenecks due to disk-based processing
- Batch processing doesn't serve all needs
- Programming can be verbose and complex
- Scheduling of the tasks is slow as there is not much reuse of resources
- No good way to do real-time event processing
- Machine learning takes too long as usually ML involves iterative processing and MR is too slow for this
In the next section, we will look at Apache Spark, which has already solved some of the limitations of Hadoop technologies.