
RDDs are immutable and every operation creates a new RDD. Now, the two main operations that you can perform on an RDD are Transformations and Actions.
Transformations change the elements in the RDD such as splitting the input element, filtering out elements, and performing calculations of some sort. Several transformations can be performed in a sequence; however no execution takes place during the planning.
The reasoning behind the lazy evaluation is that Spark can look at all the transformations and plan the execution, making use of the understanding the Driver has of all the operations. For instance, if a filter transformation is applied immediately after some other transformation, Spark will optimize the execution so that each Executor performs the transformations on each partition of data efficiently. Now, this is possible only when Spark is waiting until something needs to be executed.
Actions are operations, which actually trigger the computations. Until an action operation is encountered, the execution plan within the spark program is created in the form of a DAG and does nothing. Clearly, there could be several transformations of all sorts within the execution plan, but nothing happens until you perform an action.
The following is a depiction of the various operations on some arbitrary data where we just wanted to remove all pens and bikes and just count cars. Each print statement is an action which triggers the execution of all the transformation steps in the DAG based execution plan until that point as shown in the following diagram:
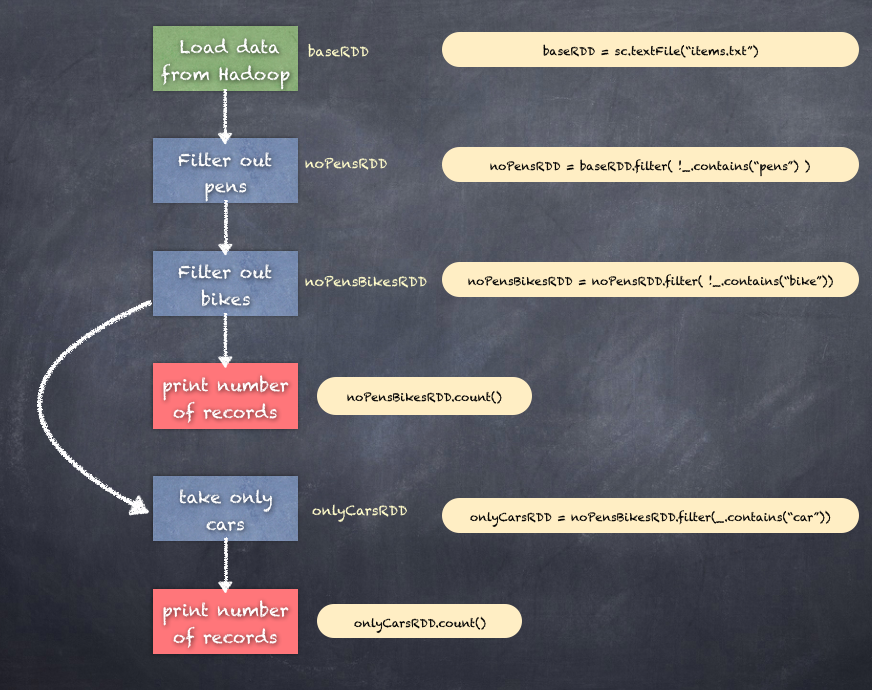
For example, an action count on a directed acyclic graph of transformations triggers the execution of the transformation all the way up to the base RDD. If there is another action performed, then there is a new chain of executions that could take place. This is a clear case of why any caching that could be done at different stages in the directed acyclic graph will greatly speed up the next execution of the program. Another way that the execution is optimized is through the reuse of the shuffle files from the previous execution.
Another example is the collect action that collects or pulls all the data from all the nodes to the driver. You could use a partial function when invoking collect to selectively pull the data.