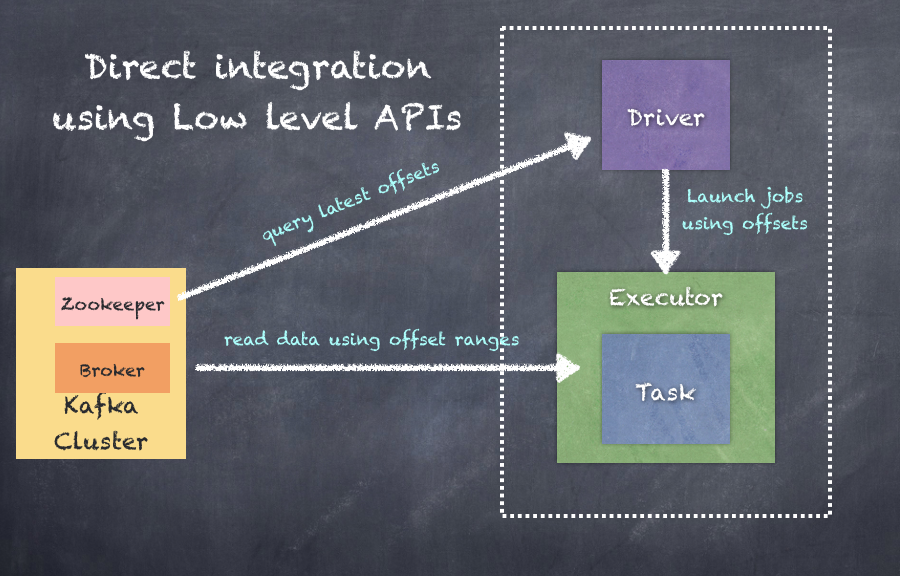
The direct stream based approach is the newer approach with respect to Kafka integration and works by using the driver to connect to the brokers directly and pull events. The key aspect is that using direct stream API, Spark tasks work on a 1:1 ratio when looking at spark partition to Kafka topic/partition. No dependency on HDFS or WAL makes it flexible. Also, since now we can have direct access to offsets, we can use idempotent or transactional approach for exactly once processing.
Create an input stream that directly pulls messages from Kafka brokers without using any receiver. This stream can guarantee that each message from Kafka is included in transformations exactly once.
Properties of a direct stream are as follows:
- No receivers: This stream does not use any receiver, but rather directly queries Kafka.
- Offsets: This does not use Zookeeper to store offsets, and the consumed offsets are tracked by the stream itself. You can access the offsets used in each batch from the generated RDDs.
- Failure recovery: To recover from driver failures, you have to enable checkpointing in the StreamingContext.
- End-to-end semantics: This stream ensures that every record is effectively received and transformed exactly once, but gives no guarantees on whether the transformed data are outputted exactly once.
You can create a direct stream by using KafkaUtils, createDirectStream() API as follows:
def createDirectStream[
K: ClassTag, //K type of Kafka message key
V: ClassTag, //V type of Kafka message value
KD <: Decoder[K]: ClassTag, //KD type of Kafka message key decoder
VD <: Decoder[V]: ClassTag, //VD type of Kafka message value decoder
R: ClassTag //R type returned by messageHandler
](
ssc: StreamingContext, //StreamingContext object
KafkaParams: Map[String, String],
/*
KafkaParams Kafka <a href="http://Kafka.apache.org/documentation.html#configuration">
configuration parameters</a>. Requires "metadata.broker.list" or "bootstrap.servers"
to be set with Kafka broker(s) (NOT zookeeper servers) specified in
host1:port1,host2:port2 form.
*/
fromOffsets: Map[TopicAndPartition, Long], //fromOffsets Per- topic/partition Kafka offsets defining the (inclusive) starting point of the stream
messageHandler: MessageAndMetadata[K, V] => R //messageHandler Function for translating each message and metadata into the desired type
): InputDStream[R] //DStream of R
Shown in the following is an example of a direct stream created to pull data from Kafka topics and create a DStream:
val topicsSet = topics.split(",").toSet
val KafkaParams : Map[String, String] =
Map("metadata.broker.list" -> brokers,
"group.id" -> groupid )
val rawDstream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, KafkaParams, topicsSet)
Shown in the following is an illustration of how the driver pulls offset information from Zookeeper and directs the executors to launch tasks to pull events from brokers based on the offset ranges prescribed by the driver: