
You can write Spark codes using SparkR too that supports distributed machine learning using MLlib. In summary, SparkR inherits many benefits from being tightly integrated with Spark including the following:
- Supports various data sources API: SparkR can be used to read in data from a variety of sources including Hive tables, JSON files, RDBMS, and Parquet files.
- DataFrame optimizations: SparkR DataFrames also inherit all of the optimizations made to the computation engine in terms of code generation, memory management, and so on. From the following graph, it can be observed that the optimization engine of Spark enables SparkR competent with Scala and Python:
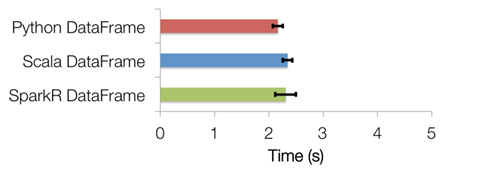
Figure 18: SparkR DataFrame versus Scala/Python DataFrame
- Scalability: Operations executed on SparkR DataFrames get automatically distributed across all the cores and machines available on the Spark cluster. Thus, SparkR DataFrames can be used on terabytes of data and run on clusters with thousands of machines.