
As you already know, Spark jobs can be run in local mode. This is sometimes called pseudocluster mode of execution. This is also nondistributed and single JVM-based deployment mode where Spark issues all the execution components, for example, driver program, executor, LocalSchedulerBackend, and master, into your single JVM. This is the only mode where the driver itself is used as an executor. The following figure shows the high-level architecture of the local mode for submitting your Spark jobs:
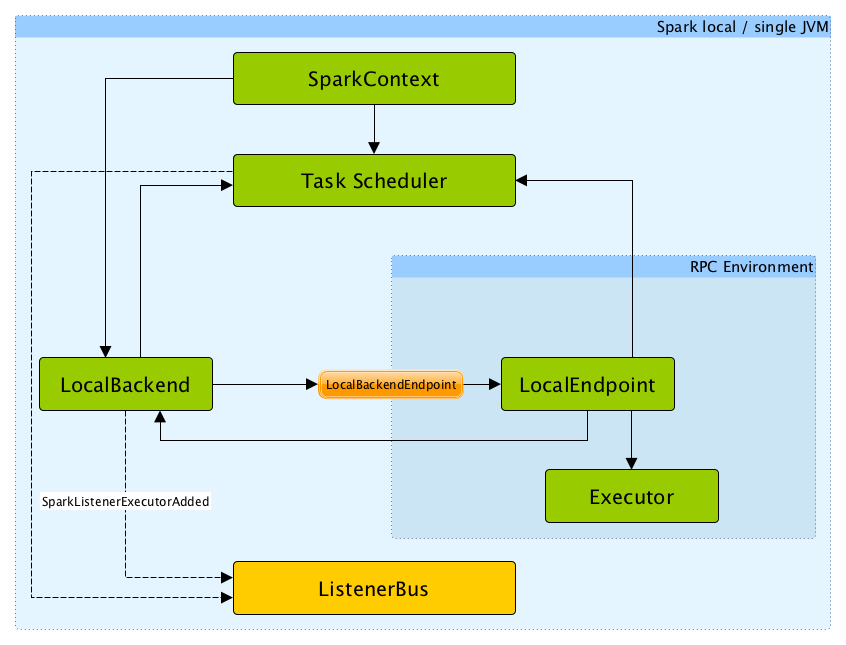
Is it too surprising? No, I guess, since you can achieve some short of parallelism as well, where the default parallelism is the number of threads (aka Core used) as specified in the master URL, that is, local [4] for 4 cores/threads and local [*] for all the available threads. We will discuss this topic later in this chapter.