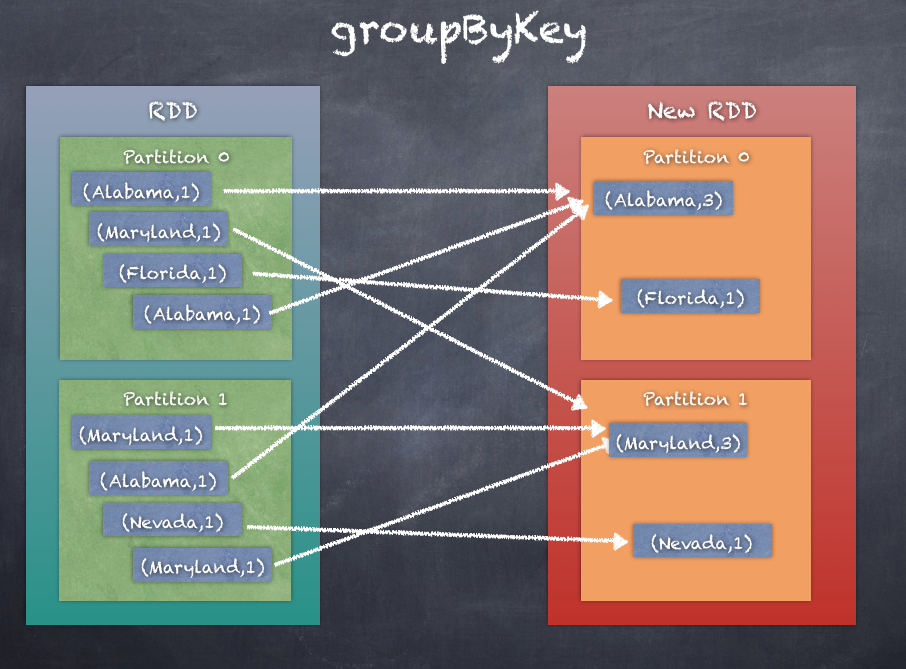
groupByKey groups the values for each key in the RDD into a single sequence. groupByKey also allows controlling the partitioning of the resulting key-value pair RDD by passing a partitioner. By default, a HashPartitioner is used but a custom partitioner can be given as an argument. The ordering of elements within each group is not guaranteed, and may even differ each time the resulting RDD is evaluated.
groupByKey can be invoked either using a custom partitioner or just using the default HashPartitioner as shown in the following code snippet:
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
groupByKey works by sending all elements of the partitions to the partition based on the partitioner so that all pairs of (key - value) for the same key are collected in the same partition. Once this is done, the aggregation operation can be done easily.
Shown here is an illustration of what happens when groupByKey is called: