
When running SQL queries from another programming language (for example, Java), the result is returned as a DataFrame. A DataFrame is a distributed collection of data organized into named columns. A dataset, on the other hand, is an interface that tries to provide the benefits of RDDs out of the Spark SQL. A dataset can be constructed from some JVM objects such as primitive types (for example, String, Integer, and Long), Scala case classes, and Java Beans. An ML pipeline involves a number of the sequences of dataset transformations and models. Each transformation takes an input dataset and outputs the transformed dataset, which becomes the input to the next stage. Consequently, the data import and export are the start and end points of an ML pipeline. To make these easier, Spark MLlib and Spark ML provide import and export utilities of a dataset, DataFrame, RDD, and model for several application-specific types, including:
- LabeledPoint for classification and regression
- LabeledDocument for cross-validation and Latent Dirichlet Allocation (LDA)
- Rating and ranking for collaborative filtering
However, real datasets usually contain numerous types, such as user ID, item IDs, labels, timestamps, and raw records. Unfortunately, the current utilities of Spark implementation cannot easily handle datasets consisting of these types, especially time-series datasets. The feature transformation usually forms the majority of a practical ML pipeline. A feature transformation can be viewed as appending or dropping a new column created from existing columns.
In the following figure, you will see that the text tokenizer breaks a document into a bag of words. After that, the TF-IDF algorithm converts a bag of words into a feature vector. During the transformations, the labels need to be preserved for the model-fitting stage:
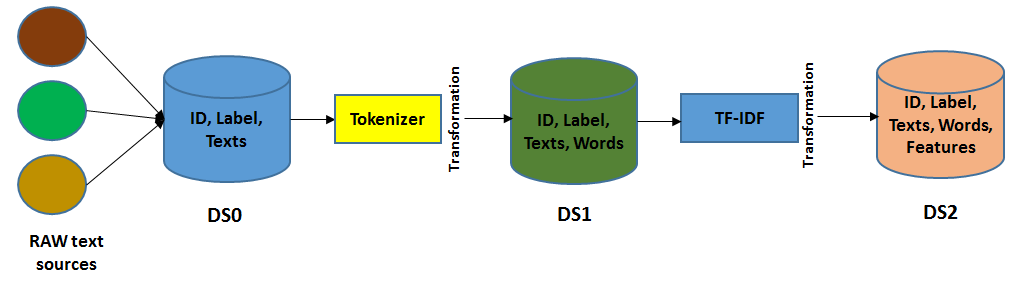
Here, the ID, text, and words are conceded during the transformations steps. They are useful in making predictions and model inspection. However, they are actually unnecessary for model fitting to state. These also don't provide much information if the prediction dataset contains only the predicted labels. Consequently, if you want to inspect the prediction metrics, such as the accuracy, precision, recall, weighted true positives, and weighted false positives, it is quite useful to look at the predicted labels along with the raw input text and tokenized words. The same recommendation also applies to other machine learning applications using Spark ML and Spark MLlib.
Therefore, an easy conversion between RDDs, dataset, and DataFrames has been made possible for in-memory, disk, or external data sources such as Hive and Avro. Although creating new columns from existing columns is easy with user-defined functions, the manifestation of dataset is a lazy operation. In contrast, the dataset supports only some standard data types. However, to increase the usability and to make a better fit for the machine learning model, Spark has also added the support for the Vector type as a user-defined type that supports both dense and sparse feature vectors under mllib.linalg.DenseVector and mllib.linalg.Vector.
Complete DataFrame, dataset, and RDD examples in Java, Scala, and Python can be found in the examples/src/main/ folder under the Spark distribution. Interested readers can refer to Spark SQL's user guide at http://spark.apache.org/docs/latest/sql-programming-guide.html to learn more about DataFrame, dataset, and the operations they support.