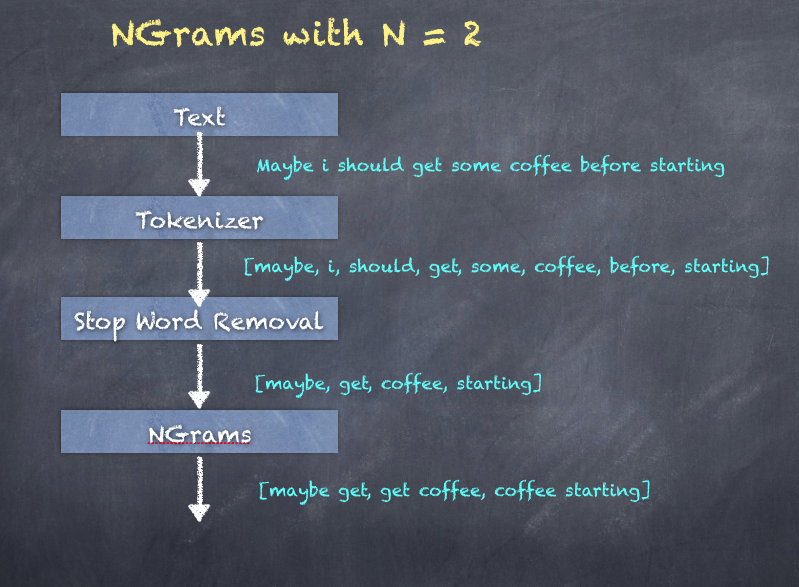
NGrams are word combinations created as sequences of words. N stands for the number of words in the sequence. For example, 2-gram is two words together, 3-gram is three words together. setN() is used to specify the value of N.
In order to generate NGrams, you need to import the package:
import org.apache.spark.ml.feature.NGram
First, you need to initialize an NGram generator specifying the input column and the output column. Here, we are choosing the filtered words column created by the StopWordsRemover and generating an output column for the filtered words after removal of stop words:
scala> val ngram = new NGram().setN(2).setInputCol("filteredWords").setOutputCol("ngrams")
ngram: org.apache.spark.ml.feature.NGram = ngram_e7a3d3ab6115
Next, invoking the transform() function on the input dataset yields an output dataset:
scala> val nGramDF = ngram.transform(noStopWordsDF)
nGramDF: org.apache.spark.sql.DataFrame = [id: int, sentence: string ... 3 more fields]
The following is the output dataset showing the input column ID, sentence, and the output column ngram, which contain the sequence of n-grams:
scala> nGramDF.show(false)
|id|sentence |words |filteredWords |ngrams |
|1 |Hello there, how do you like the book so far? |[hello, there,, how, do, you, like, the, book, so, far?] |[hello, there,, like, book, far?] |[hello there,, there, like, like book, book far?] |
|2 |I am new to Machine Learning |[i, am, new, to, machine, learning] |[new, machine, learning] |[new machine, machine learning] |
|3 |Maybe i should get some coffee before starting |[maybe, i, should, get, some, coffee, before, starting] |[maybe, get, coffee, starting] |[maybe get, get coffee, coffee starting] |
|4 |Coffee is best when you drink it hot |[coffee, is, best, when, you, drink, it, hot] |[coffee, best, drink, hot] |[coffee best, best drink, drink hot] |
|5 |Book stores have coffee too so i should go to a book store|[book, stores, have, coffee, too, so, i, should, go, to, a, book, store]|[book, stores, coffee, go, book, store]|[book stores, stores coffee, coffee go, go book, book store]|
The following is the output dataset showing the sentence and 2-grams:
scala> nGramDF.select("sentence", "ngrams").show(5,false)
|sentence |ngrams |
|Hello there, how do you like the book so far? |[hello there,, there, like, like book, book far?] |
|I am new to Machine Learning |[new machine, machine learning] |
|Maybe i should get some coffee before starting |[maybe get, get coffee, coffee starting] |
|Coffee is best when you drink it hot |[coffee best, best drink, drink hot] |
|Book stores have coffee too so i should go to a book store|[book stores, stores coffee, coffee go, go book, book store]|
The diagram of an NGram is as follows, which shows 2-grams generated from the sentence after tokenizing and removing stop words: