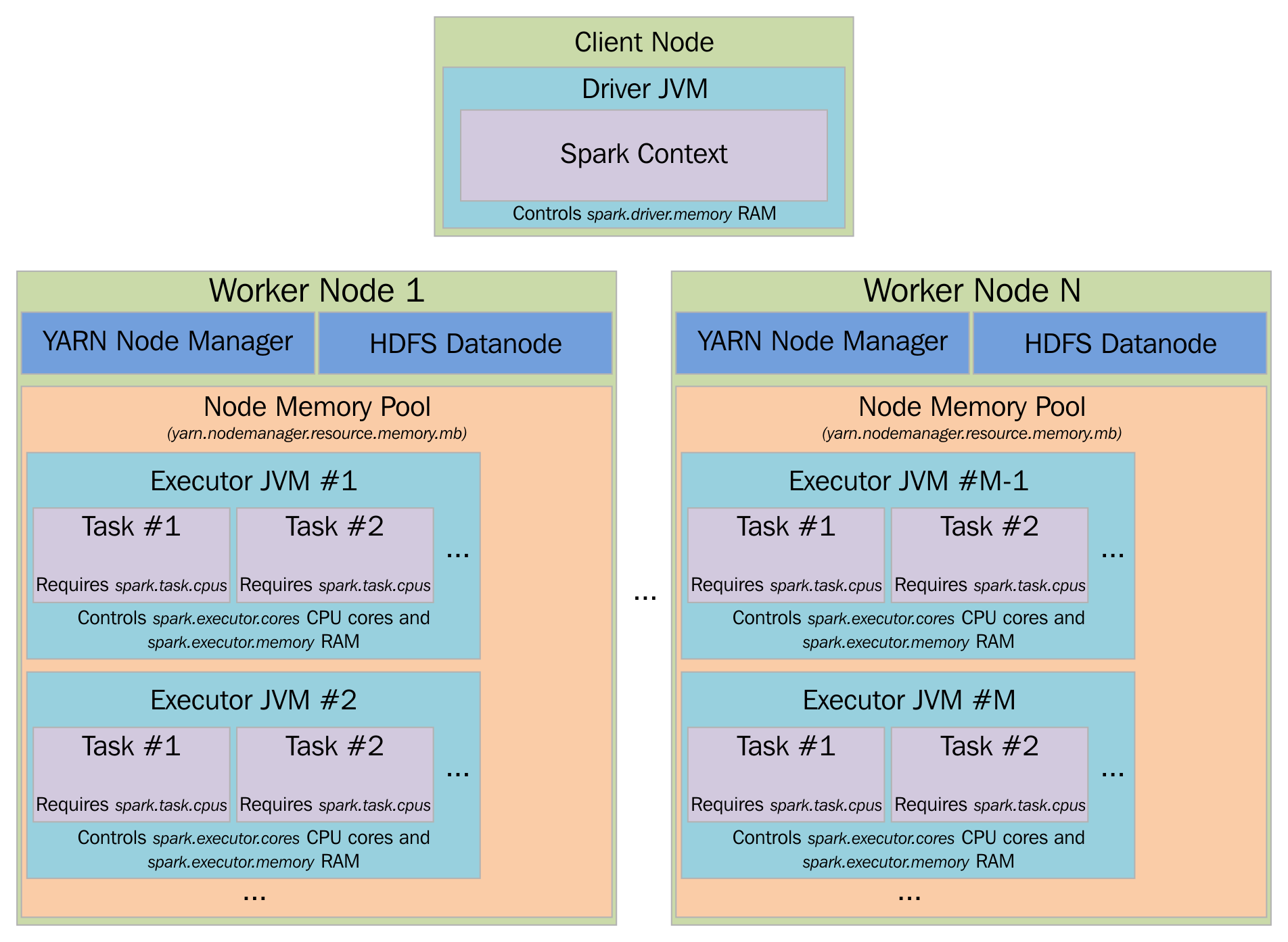
The Spark context can be defined through the Spark configuration object (that is, SparkConf) and a Spark URL. First, the purpose of the Spark context is to connect the Spark cluster manager in which your Spark jobs will be running. The cluster or resource manager then allocates the required resources across the computing nodes for your application. The second task of the cluster manager is to allocate the executors across the cluster worker nodes so that your Spark jobs get executed. Third, the resource manager also copies the driver program (aka the application JAR file, R code, or Python script) to the computing nodes. Finally, the computing tasks are assigned to the computing nodes by the resource manager.
The following subsections describe the possible Apache Spark cluster manager options available with the current Spark version (that is, Spark 2.1.0 during the writing of this book). To know about the resource management by a resource manager (aka the cluster manager), the following shows how YARN manages all its underlying computing resources. However, this is same for any cluster manager (for example, Mesos or YARN) you use: