
Like Scala interactive shell, an interactive shell is also available for Python. You can execute Python code from Spark root folder as follows:
$ cd $SPARK_HOME
$ ./bin/pyspark
If the command went fine, you should observer the following screen on Terminal (Ubuntu):
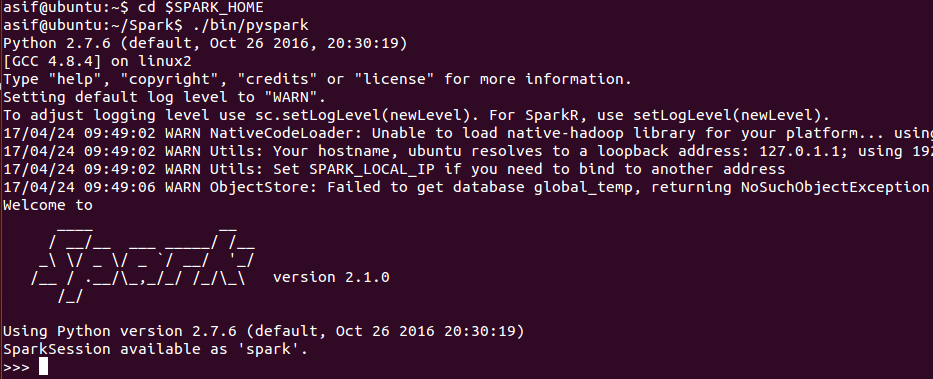
Now you can enjoy Spark using the Python interactive shell. This shell might be sufficient for experimentations and developments. However, for production level, you should use a standalone application.
PySpark should be available in the system path by now. After writing the Python code, one can simply run the code using the Python command, then it runs in local Spark instance with default configurations:
$ python <python_file.py>
Note that the current distribution of Spark is only Python 2.7+ compatible. Hence, we will have been strict on this.
Furthermore, it is better to use the spark-submit script if you want to pass the configuration values at runtime. The command is pretty similar to the Scala one:
$ cd $SPARK_HOME
$ ./bin/spark-submit --master local[*] <python_file.py>
The configuration values can be passed at runtime, or alternatively, they can be changed in the conf/spark-defaults.conf file. After configuring the Spark config file, the changes also get reflected while running PySpark applications using a simple Python command.
However, unfortunately, at the time of this writing, there's no pip install advantage for using PySpark. But it is expected to be available in the Spark 2.2.0 release (for more, refer to https://issues.apache.org/jira/browse/SPARK-1267). The reason why there is no pip install for PySpark can be found in the JIRA ticket at https://issues.apache.org/jira/browse/SPARK-1267.