combineByKey is very similar to aggregateByKey; in fact, combineByKey internally invokes combineByKeyWithClassTag, which is also invoked by aggregateByKey. As in aggregateByKey, the combineByKey also works by applying an operation within each partition and then between combiners.
combineByKey turns an RDD[K,V] into an RDD[K,C], where C is a list of Vs collected or combined under the name key K.
There are three functions expected when you call combineByKey.
- createCombiner, which turns a V into C, which is a one element list
- mergeValue to merge a V into a C by appending the V to the end of the list
- mergeCombiners to combine two Cs into one
combineByKey can be invoked either using a custom partitioner or just using the default HashPartitioner as shown in the following code snippet:
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]
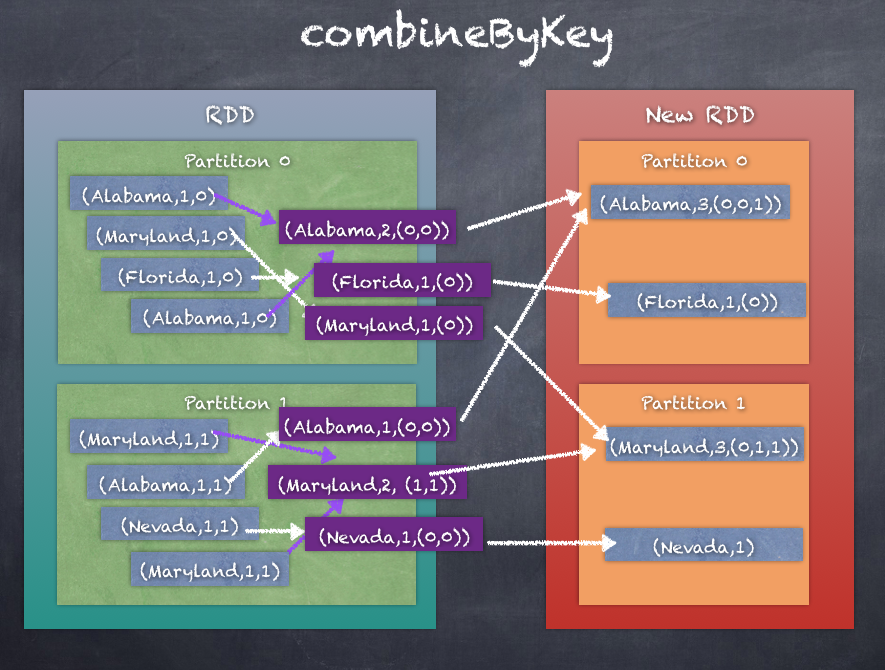
combineByKey works by performing an aggregation within the partition operating on all elements of each partition and then applies another aggregation logic when combining the partitions themselves. Ultimately, all pairs of (key - value) for the same Key are collected in the same partition however the aggregation as to how it is done and the output generated is not fixed as in groupByKey and reduceByKey, but is more flexible and customizable when using combineByKey.
The following diagram is an illustration of what happens when combineBykey is called: