Resilient Distributed Datasets (RDDs) are the fundamental object used in Apache Spark. RDDs are immutable collections representing datasets and have the inbuilt capability of reliability and failure recovery. By nature, RDDs create new RDDs upon any operation such as transformation or action. They also store the lineage, which is used to recover from failures. We have also seen in the previous chapter some details about how RDDs can be created and what kind of operations can be applied to RDDs.
The following is a simply example of the RDD lineage:

Let's start looking at the simplest RDD again by creating a RDD from a sequence of numbers:
scala> val rdd_one = sc.parallelize(Seq(1,2,3,4,5,6))
rdd_one: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:25
scala> rdd_one.take(100)
res45: Array[Int] = Array(1, 2, 3, 4, 5, 6)
The preceding example shows RDD of integers and any operation done on the RDD results in another RDD. For example, if we multiply each element by 3, the result is shown in the following snippet:
scala> val rdd_two = rdd_one.map(i => i * 3)
rdd_two: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[29] at map at <console>:27
scala> rdd_two.take(10)
res46: Array[Int] = Array(3, 6, 9, 12, 15, 18)
Let's do one more operation, adding 2 to each element and also print all three RDDs:
scala> val rdd_three = rdd_two.map(i => i+2)
rdd_three: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[30] at map at <console>:29
scala> rdd_three.take(10)
res47: Array[Int] = Array(5, 8, 11, 14, 17, 20)
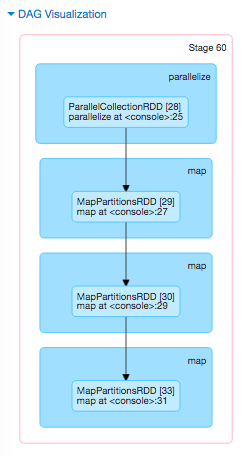
An interesting thing to look at is the lineage of each RDD using the toDebugString function:
scala> rdd_one.toDebugString
res48: String = (8) ParallelCollectionRDD[28] at parallelize at <console>:25 []
scala> rdd_two.toDebugString
res49: String = (8) MapPartitionsRDD[29] at map at <console>:27 []
| ParallelCollectionRDD[28] at parallelize at <console>:25 []
scala> rdd_three.toDebugString
res50: String = (8) MapPartitionsRDD[30] at map at <console>:29 []
| MapPartitionsRDD[29] at map at <console>:27 []
| ParallelCollectionRDD[28] at parallelize at <console>:25 []
The following is the lineage shown in the Spark web UI:
RDD does not need to be the same datatype as the first RDD (integer). The following is a RDD which writes a different datatype of a tuple of (string, integer).
scala> val rdd_four = rdd_three.map(i => ("str"+(i+2).toString, i-2))
rdd_four: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[33] at map at <console>:31
scala> rdd_four.take(10)
res53: Array[(String, Int)] = Array((str7,3), (str10,6), (str13,9), (str16,12), (str19,15), (str22,18))
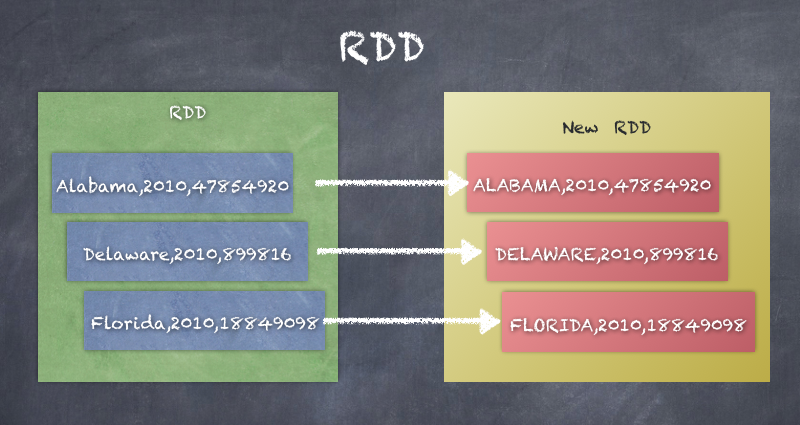
The following is a RDD of the StatePopulation file where each record is converted to upperCase.
scala> val upperCaseRDD = statesPopulationRDD.map(_.toUpperCase)
upperCaseRDD: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[69] at map at <console>:27
scala> upperCaseRDD.take(10)
res86: Array[String] = Array(STATE,YEAR,POPULATION, ALABAMA,2010,4785492, ALASKA,2010,714031, ARIZONA,2010,6408312, ARKANSAS,2010,2921995, CALIFORNIA,2010,37332685, COLORADO,2010,5048644, DELAWARE,2010,899816, DISTRICT OF COLUMBIA,2010,605183, FLORIDA,2010,18849098)
The following is a diagram of the preceding transformation: