
StringIndexer encodes a string column of labels to a column of label indices. The indices are in [0, numLabels), ordered by label frequencies, so the most frequent label gets index 0. If the input column is numeric, we cast it to string and index the string values. When downstream pipeline components such as estimator or transformer make use of this string-indexed label, you must set the input column of the component to this string-indexed column name. In many cases, you can set the input column with setInputCol. Suppose you have some categorical data in the following format:

Now, we want to index the name column so that the most frequent name (that is, Jason in our case) gets index 0. To make this, Spark provides StringIndexer API for doing so. For our example, this can be done, as follows:
At first, let's create a simple DataFrame for the preceding table:
val df = spark.createDataFrame(
Seq((0, "Jason", "Germany"),
(1, "David", "France"),
(2, "Martin", "Spain"),
(3, "Jason", "USA"),
(4, "Daiel", "UK"),
(5, "Moahmed", "Bangladesh"),
(6, "David", "Ireland"),
(7, "Jason", "Netherlands"))).toDF("id", "name", "address")
Now let's index the name column, as follows:
val indexer = new StringIndexer()
.setInputCol("name")
.setOutputCol("label")
.fit(df)
Now let's downstream the indexer using the transformer, as follows:
val indexed = indexer.transform(df)
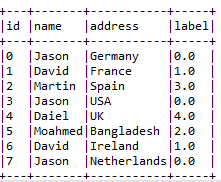
Now let's check to make sure if it works properly:
indexed.show(false)
Another important transformer is the OneHotEncoder, which is frequently used in machine learning tasks for handling categorical data. We will see how to work with this transformer in the next section.