
A Resilient Distributed Dataset (RDD) is an immutable, distributed collection of objects. Spark RDDs are resilient or fault tolerant, which enables Spark to recover the RDD in the face of failures. Immutability makes the RDDs read-only once created. Transformations allow operations on the RDD to create a new RDD but the original RDD is never modified once created. This makes RDDs immune to race conditions and other synchronization problems.
The distributed nature of the RDDs works because an RDD only contains a reference to the data, whereas the actual data is contained within partitions across the nodes in the cluster.
A RDD is actually a dataset that has been partitioned across the cluster and the partitioned data could be from HDFS (Hadoop Distributed File System), HBase table, Cassandra table, Amazon S3.
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a partitioner for key-value RDDs (for example, to say that the RDD is hash partitioned)
- Optionally, a list of preferred locations to compute each split on (for example, block locations for an HDFS file)
Take a look at the following diagram:
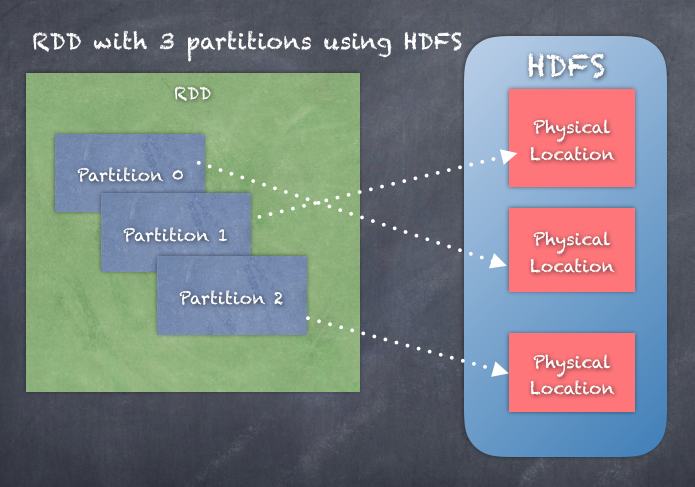
Within your program, the driver treats the RDD object as a handle to the distributed data. It is analogous to a pointer to the data, rather than the actual data used, to reach the actual data when it is required.
The RDD by default uses the hash partitioner to partition the data across the cluster. The number of partitions is independent of the number of nodes in the cluster. It could very well happen that a single node in the cluster has several partitions of data. The number of partitions of data that exist is entirely dependent on how many nodes your cluster has and the size of the data. If you look at the execution of tasks on the nodes, then a task running on an executor on the worker node could be processing the data which is available on the same local node or a remote node. This is called the locality of the data, and the executing task chooses the most local data possible.
PROCESS_LOCAL > NODE_LOCAL > NO_PREF > RACK_LOCAL > ANY
There is no guarantee of how many partitions a node might get. This affects the processing efficiency of any executor, because if you have too many partitions on a single node processing multiple partitions, then the time taken to process all the partitions also grows, overloading the cores on the executor, and thus slowing down the entire stage of processing, which directly slows down the entire job. In fact, partitioning is one of the main tuning factors to improve the performance of a Spark job. Refer to the following command:
class RDD[T: ClassTag]
Let's look further into what an RDD will look like when we load data. The following is an example of how Spark uses different workers to load different partitions or splits of the data:
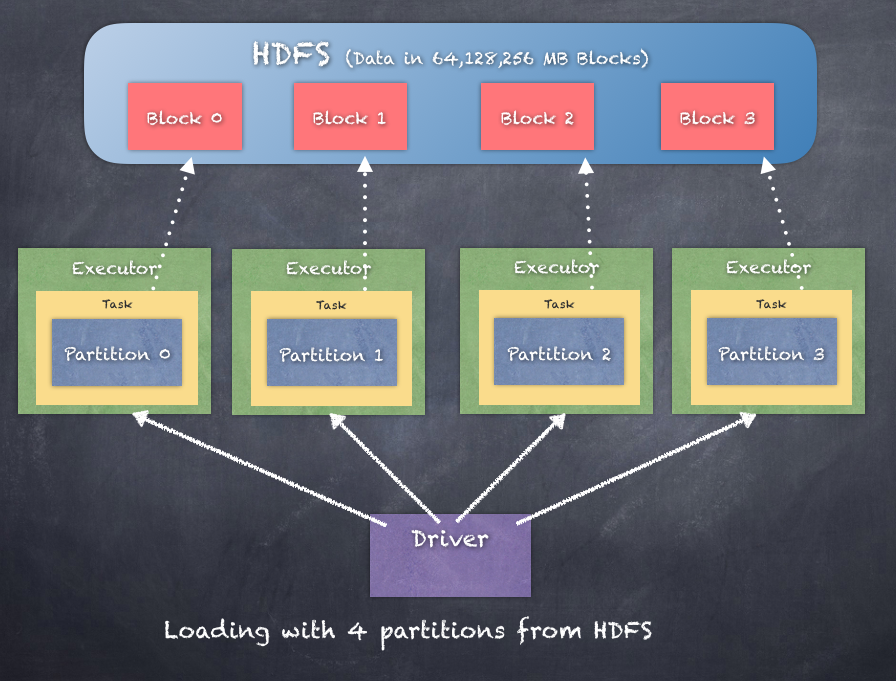
No matter how the RDD is created, the initial RDD is typically called the base RDD and any subsequent RDDs created by the various operations are part of the lineage of the RDDs. This is another very important aspect to remember, as the secret to fault tolerance and recovery is that the Driver maintains the lineage of the RDDs and can execute the lineage to recover any lost blocks of the RDDs.
The following is an example showing multiple RDDs created as a result of operations. We start with the Base RDD, which has 24 items and derive another RDD carsRDD that contains only items (3) which match cars:

Next, we will see how to create RDDs