
Transformations on a DStream are similar to the transformations applicable to a Spark core RDD. Since DStream consists of RDDs, a transformation also applies to each RDD to generate a transformed RDD for the RDD, and then a transformed DStream is created. Every transformation creates a specific DStream derived class.
The following diagram shows the hierarchy of DStream classes starting from the parent DStream class. We can also see the different classes inheriting from the parent class:
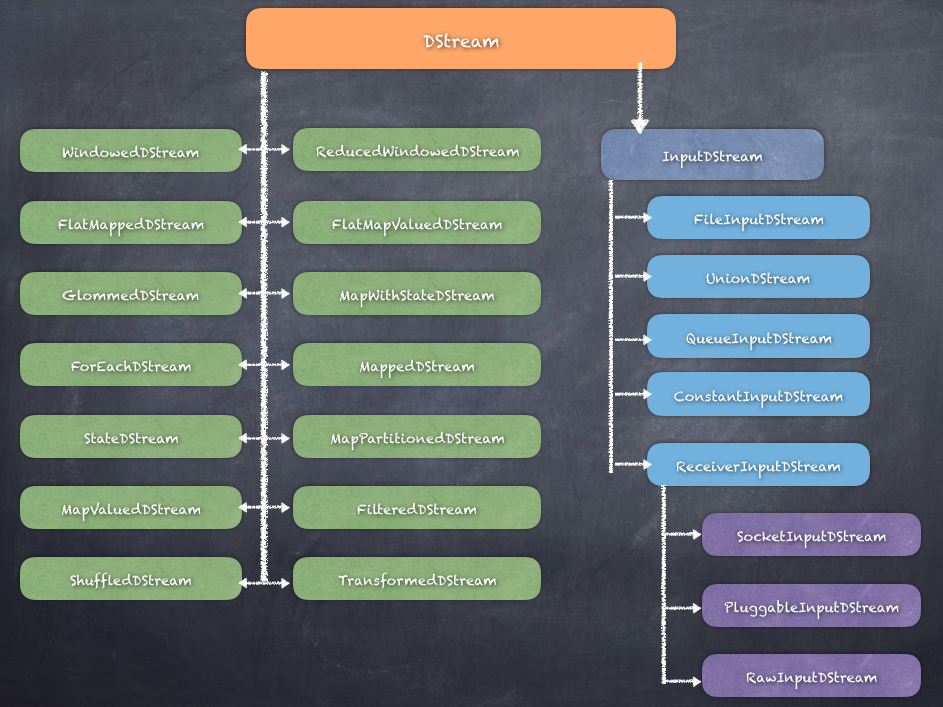
There are a lot of DStream classes purposely built for the functionality. Map transformations, window functions, reduce actions, and different types of input streams are all implemented using different class derived from DStream class.
Shown in the following is an illustration of a transformation on a base DStream to generate a filtered DStream. Similarly, any transformation is applicable to a DStream:

Refer to the following table for the types of transformations possible.
| Transformation | Meaning |
|---|---|
| map(func) | This applies the transformation function to each element of the DStream and returns a new DStream. |
| flatMap(func) | This is similar to map; however, just like RDD's flatMap versus map, using flatMap operates on each element and applies flatMap, producing multiple output items per each input. |
| filter(func) | This filters out the records of the DStream to return a new DStream. |
| repartition(numPartitions) | This creates more or fewer partitions to redistribute the data to change the parallelism. |
| union(otherStream) | This combines the elements in two source DStreams and returns a new DStream. |
| count() | This returns a new DStream by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | This returns a new DStream by applying the reduce function on each element of the source DStream. |
| countByValue() | This computes the frequency of each key and returns a new DStream of (key, long) pairs. |
| reduceByKey(func, [numTasks]) | This aggregates the data by key in the source DStream's RDDs and returns a new DStream of (key, value) pairs. |
| join(otherStream, [numTasks]) | This joins two DStreams of (K, V) and (K, W) pairs and returns a new DStream of (K, (V, W)) pairs combining the values from both DStreams. |
| cogroup(otherStream, [numTasks]) | cogroup(), when called on a DStream of (K, V) and (K, W) pairs, will return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | This applies a transformation function on each RDD of the source DStream and returns a new DStream. |
| updateStateByKey(func) | This updates the state for each key by applying the given function on the previous state of the key and the new values for the key. Typically, it used to maintain a state machine. |