
A typical machine learning application involves several steps ranging from the input, processing, to output, which forms a scientific workflow, as shown in Figure 1. The following steps are involved in a typical machine learning application:
- Load the sample data.
- Parse the data into the input format for the algorithm.
- Preprocess the data and handle the missing values.
- Split the data into two sets: one for building the model (training dataset) and one for testing the model (validation dataset).
- Run the algorithm to build or train your ML model.
- Make predictions with the training data and observe the results.
- Test and evaluate the model with the test data or, alternatively, validate the model using a cross-validator technique using the third dataset, called the validation dataset.
- Tune the model for better performance and accuracy.
- Scale up the model so that it will be able to handle massive datasets in future.
- Deploy the ML model in commercialization.
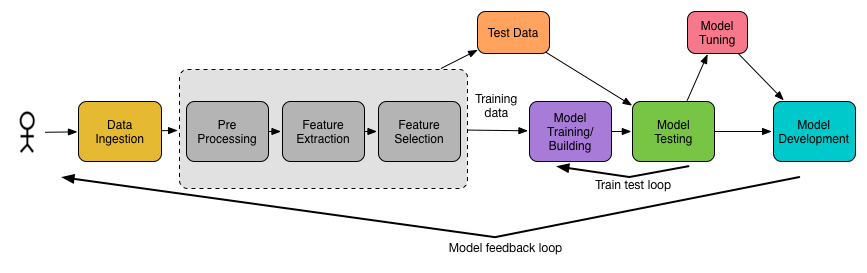
Often, the machine learning algorithms have some ways to handle skewness in the datasets. That skewness is sometimes immense though. In step 4, the experimental dataset is randomly split, often into a training set and a test set, which is called sampling. The training dataset is used to train the model, whereas the test dataset is used to evaluate the performance of the best model at the very end. The better practice is to use the training dataset as much as you can to increase generalization performance. On the other hand, it is recommended to use the test dataset only once, to avoid the overfitting problem while computing the prediction error and the related metrics.