
Text classification is one of the most widely used paradigms in the field of machine learning and is useful in use cases such as spam detection and email classification and just like any other machine learning algorithm, the workflow is built of Transformers and algorithms. In the field of text processing, preprocessing steps such as stop-word removal, stemming, tokenizing, n-gram extraction, TF-IDF feature weighting come into play. Once the desired processing is complete, the models are trained to classify the documents into two or more classes.
Binary classification is the classification of inputting two output classes such as spam/not spam and a given credit card transaction is fraudulent or not. Multiclass classification can generate multiple output classes such as hot, cold, freezing, and rainy. There is another technique called Multilabel classification, which can generate multiple labels such as speed, safety, and fuel efficiency can be produced from descriptions of car features.
For this purpose, we will using a 10k sample dataset of tweets and we will use the preceding techniques on this dataset. Then, we will tokenize the text lines into words, remove stop words, and then use CountVectorizer to build a vector of the words (features).
Then we will split the data into training (80%)-testing (20%) and train a Logistic Regression model. Finally, we will evaluate against the test data and look at how it is performed.
The steps in the workflow are shown in the following diagram:
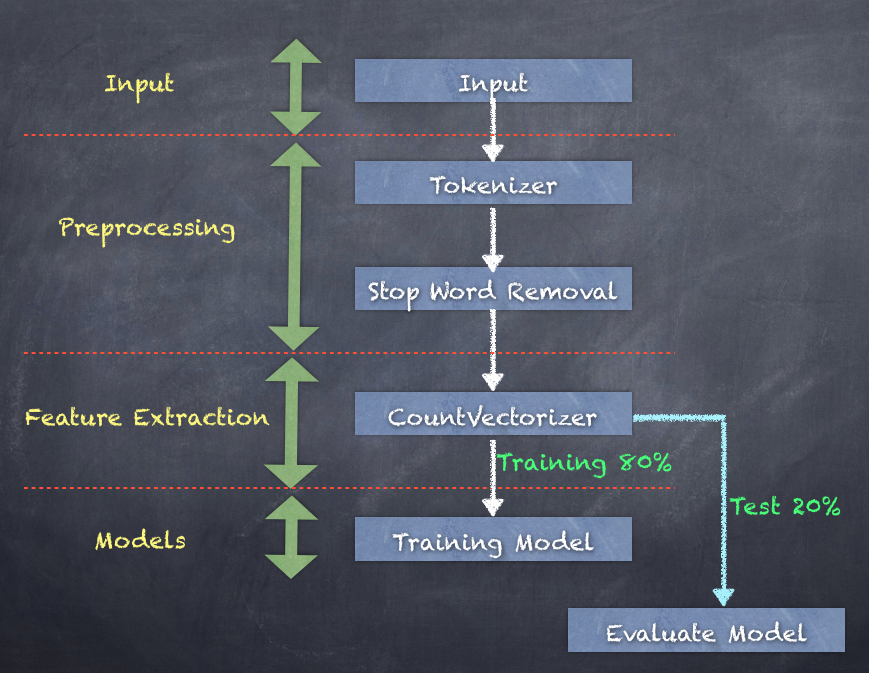
Step 1. Load the input text data containing 10k tweets along with label and ID:
scala> val inputText = sc.textFile("Sentiment_Analysis_Dataset10k.csv")
inputText: org.apache.spark.rdd.RDD[String] = Sentiment_Analysis_Dataset10k.csv MapPartitionsRDD[1722] at textFile at <console>:77
Step 2. Convert the input lines to a DataFrame:
scala> val sentenceDF = inputText.map(x => (x.split(",")(0), x.split(",")(1), x.split(",")(2))).toDF("id", "label", "sentence")
sentenceDF: org.apache.spark.sql.DataFrame = [id: string, label: string ... 1 more field]
Step 3. Transform the data into words using a Tokenizer with white space delimiter:
scala> import org.apache.spark.ml.feature.Tokenizer
import org.apache.spark.ml.feature.Tokenizer
scala> val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
tokenizer: org.apache.spark.ml.feature.Tokenizer = tok_ebd4c89f166e
scala> val wordsDF = tokenizer.transform(sentenceDF)
wordsDF: org.apache.spark.sql.DataFrame = [id: string, label: string ... 2 more fields]
scala> wordsDF.show(5, true)
| id|label| sentence| words|
| 1| 0|is so sad for my ...|[is, so, sad, for...|
| 2| 0|I missed the New ...|[i, missed, the, ...|
| 3| 1| omg its already ...|[, omg, its, alre...|
| 4| 0| .. Omgaga. Im s...|[, , .., omgaga.,...|
| 5| 0|i think mi bf is ...|[i, think, mi, bf...|
Step 4. Remove stop words and create a new DataFrame with the filtered words:
scala> import org.apache.spark.ml.feature.StopWordsRemover
import org.apache.spark.ml.feature.StopWordsRemover
scala> val remover = new StopWordsRemover().setInputCol("words").setOutputCol("filteredWords")
remover: org.apache.spark.ml.feature.StopWordsRemover = stopWords_d8dd48c9cdd0
scala> val noStopWordsDF = remover.transform(wordsDF)
noStopWordsDF: org.apache.spark.sql.DataFrame = [id: string, label: string ... 3 more fields]
scala> noStopWordsDF.show(5, true)
| id|label| sentence| words| filteredWords|
| 1| 0|is so sad for my ...|[is, so, sad, for...|[sad, apl, friend...|
| 2| 0|I missed the New ...|[i, missed, the, ...|[missed, new, moo...|
| 3| 1| omg its already ...|[, omg, its, alre...|[, omg, already, ...|
| 4| 0| .. Omgaga. Im s...|[, , .., omgaga.,...|[, , .., omgaga.,...|
| 5| 0|i think mi bf is ...|[i, think, mi, bf...|[think, mi, bf, c...|
Step 5. Create a feature vector from the filtered words:
scala> import org.apache.spark.ml.feature.CountVectorizer
import org.apache.spark.ml.feature.CountVectorizer
scala> val countVectorizer = new CountVectorizer().setInputCol("filteredWords").setOutputCol("features")
countVectorizer: org.apache.spark.ml.feature.CountVectorizer = cntVec_fdf1512dfcbd
scala> val countVectorizerModel = countVectorizer.fit(noStopWordsDF)
countVectorizerModel: org.apache.spark.ml.feature.CountVectorizerModel = cntVec_fdf1512dfcbd
scala> val countVectorizerDF = countVectorizerModel.transform(noStopWordsDF)
countVectorizerDF: org.apache.spark.sql.DataFrame = [id: string, label: string ... 4 more fields]
scala> countVectorizerDF.show(5,true)
| id|label| sentence| words| filteredWords| features|
| 1| 0|is so sad for my ...|[is, so, sad, for...|[sad, apl, friend...|(23481,[35,9315,2...|
| 2| 0|I missed the New ...|[i, missed, the, ...|[missed, new, moo...|(23481,[23,175,97...|
| 3| 1| omg its already ...|[, omg, its, alre...|[, omg, already, ...|(23481,[0,143,686...|
| 4| 0| .. Omgaga. Im s...|[, , .., omgaga.,...|[, , .., omgaga.,...|(23481,[0,4,13,27...|
| 5| 0|i think mi bf is ...|[i, think, mi, bf...|[think, mi, bf, c...|(23481,[0,33,731,...|
Step 6. Create the inputData DataFrame with just a label and the features:
scala> val inputData=countVectorizerDF.select("label", "features").withColumn("label", col("label").cast("double"))
inputData: org.apache.spark.sql.DataFrame = [label: double, features: vector]
Step 7. Split the data using a random split into 80% training and 20% testing datasets:
scala> val Array(trainingData, testData) = inputData.randomSplit(Array(0.8, 0.2))
trainingData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [label: double, features: vector]
testData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [label: double, features: vector]
Step 8. Create a Logistic Regression model:
scala> import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.classification.LogisticRegression
scala> val lr = new LogisticRegression()
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_a56accef5728
Step 9. Create a Logistic Regression model by fitting the trainingData:
scala> var lrModel = lr.fit(trainingData)
lrModel: org.apache.spark.ml.classification.LogisticRegressionModel = logreg_a56accef5728
scala> lrModel.coefficients
res160: org.apache.spark.ml.linalg.Vector = [7.499178040193577,8.794520490564185,4.837543313917086,-5.995818019393418,1.1754740390468577,3.2104594489397584,1.7840290776286476,-1.8391923375331787,1.3427471762591,6.963032309971087,-6.92725055841986,-10.781468845891563,3.9752.836891070557657,3.8758544006087523,-11.760894935576934,-6.252988307540...
scala> lrModel.intercept
res161: Double = -5.397920610780994
Step 10. Examine the model summary especially areaUnderROC, which should be > 0.90 for a good model:
scala> import org.apache.spark.ml.classification.BinaryLogisticRegressionSummary
import org.apache.spark.ml.classification.BinaryLogisticRegressionSummary
scala> val summary = lrModel.summary
summary: org.apache.spark.ml.classification.LogisticRegressionTrainingSummary = org.apache.spark.ml.classification.BinaryLogisticRegressionTrainingSummary@1dce712c
scala> val bSummary = summary.asInstanceOf[BinaryLogisticRegressionSummary]
bSummary: org.apache.spark.ml.classification.BinaryLogisticRegressionSummary = org.apache.spark.ml.classification.BinaryLogisticRegressionTrainingSummary@1dce712c
scala> bSummary.areaUnderROC
res166: Double = 0.9999231930196596
scala> bSummary.roc
res167: org.apache.spark.sql.DataFrame = [FPR: double, TPR: double]
scala> bSummary.pr.show()
| recall|precision|
| 0.0| 1.0|
| 0.2306543172990738| 1.0|
| 0.2596354944726621| 1.0|
| 0.2832387212429041| 1.0|
|0.30504929787869733| 1.0|
| 0.3304451747833881| 1.0|
|0.35255452644158947| 1.0|
| 0.3740663280549746| 1.0|
| 0.3952793546459516| 1.0|
Step 11. Transform both training and testing datasets using the trained model:
scala> val training = lrModel.transform(trainingData)
training: org.apache.spark.sql.DataFrame = [label: double, features: vector ... 3 more fields]
scala> val test = lrModel.transform(testData)
test: org.apache.spark.sql.DataFrame = [label: double, features: vector ... 3 more fields]
Step 12. Count the number of records with matching label and prediction columns. They should match for correct model evaluation else they will mismatch:
scala> training.filter("label == prediction").count
res162: Long = 8029
scala> training.filter("label != prediction").count
res163: Long = 19
scala> test.filter("label == prediction").count
res164: Long = 1334
scala> test.filter("label != prediction").count
res165: Long = 617
The results can be put into a table as shown next:
| Dataset | Total | label == prediction | label != prediction |
| Training | 8048 | 8029 ( 99.76%) | 19 (0.24%) |
| Testing | 1951 | 1334 (68.35%) | 617 (31.65%) |
While training data produced excellent matches, the testing data only had 68.35% match. Hence, there is room for improvement which can be done by exploring the model parameters.
Logistic regression is an easy-to-understand method for predicting a binary outcome using a linear combination of inputs and randomized noise in the form of a logistic random variable. Hence, Logistic Regression model can be tuned using several parameters. (The full set of parameters and how to tune such a Logistic Regression model is out of scope for this chapter.)
Some parameters that can be used to tune the model are:
- Model hyperparameters include the following parameters:
- elasticNetParam: This parameter specifies how you would like to mix L1 and L2 regularization
- regParam: This parameter determines how the inputs should be regularized before being passed in the model
- Training parameters include the following parameters:
- maxIter: This is total number of interactions before stopping
- weightCol: This is the name of the weight column to weigh certain rows more than others
- Prediction parameters include the following parameter:
- threshold: This is the probability threshold for binary prediction. This determines the minimum probability for a given class to be predicted.
We have now seen how to build a simple classification model, so any new tweet can be labeled based on the training set. Logistic Regression is only one of the models that can be used.
Other models which can be used in place of Logistic Regression are as follows:
- Decision trees
- Random Forest
- Gradient Boosted Trees
- Multilayer Perceptron