
Now, let's redesign the preceding test case by returning only the RDD of the texts in the document, as follows:
package com.chapter16.SparkTesting
import org.apache.spark._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
class wordCountRDD {
def prepareWordCountRDD(file: String, spark: SparkSession): RDD[(String, Int)] = {
val lines = spark.sparkContext.textFile(file)
lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
}
}
So, the prepareWordCountRDD() method in the preceding class returns an RDD of string and integer values. Now, if we want to test the prepareWordCountRDD() method's functionality, we can do it more explicit by extending the test class with FunSuite and BeforeAndAfterAll from the ScalaTest package of Scala. The testing works in the following ways:
- Extend the test class with FunSuite and BeforeAndAfterAll from the ScalaTest package of Scala
- Override the beforeAll() that creates Spark context
- Perform the test using the test() method and use the assert() method inside the test() method
- Override the afterAll() method that stops the Spark context
Based on the preceding steps, let's see a class for testing the preceding prepareWordCountRDD() method:
package com.chapter16.SparkTesting
import org.scalatest.{ BeforeAndAfterAll, FunSuite }
import org.scalatest.Assertions._
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.RDD
class wordCountTest2 extends FunSuite with BeforeAndAfterAll {
var spark: SparkSession = null
def tokenize(line: RDD[String]) = {
line.map(x => x.split(' ')).collect()
}
override def beforeAll() {
spark = SparkSession
.builder
.master("local[*]")
.config("spark.sql.warehouse.dir", "E:/Exp/")
.appName(s"OneVsRestExample")
.getOrCreate()
}
test("Test if two RDDs are equal") {
val input = List("To be,", "or not to be:", "that is the question-", "William Shakespeare")
val expected = Array(Array("To", "be,"), Array("or", "not", "to", "be:"), Array("that", "is", "the", "question-"), Array("William", "Shakespeare"))
val transformed = tokenize(spark.sparkContext.parallelize(input))
assert(transformed === expected)
}
test("Test for word count RDD") {
val fileName = "C:/Users/rezkar/Downloads/words.txt"
val obj = new wordCountRDD
val result = obj.prepareWordCountRDD(fileName, spark)
assert(result.count() === 214)
}
override def afterAll() {
spark.stop()
}
}
The first test says that if two RDDs materialize in two different ways, the contents should be the same. Thus, the first test should get passed. We will see this in following example. Now, for the second test, as we have seen previously, the word count of RDD is 214, but let's assume it unknown for a while. If it's 214 coincidentally, the test case should pass, which is its expected behavior.
Thus, we are expecting both tests to be passed. Now, on Eclipse, run the test suite as ScalaTest-File, as shown in the following figure:
Figure 10: running the test suite as ScalaTest-File
Now you should observe the following output (Figure 11). The output shows how many test cases we performed and how many of them passed, failed, canceled, ignored, or were (was) in pending. It also shows the time to execute the overall test.
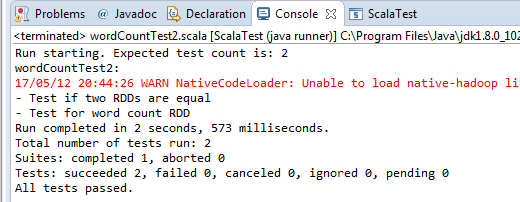
Fantastic! The test case passed. Now, let's try changing the compare value in the assertion in the two separate tests using the test() method as follows:
test("Test for word count RDD") {
val fileName = "data/words.txt"
val obj = new wordCountRDD
val result = obj.prepareWordCountRDD(fileName, spark)
assert(result.count() === 210)
}
test("Test if two RDDs are equal") {
val input = List("To be", "or not to be:", "that is the question-", "William Shakespeare")
val expected = Array(Array("To", "be,"), Array("or", "not", "to", "be:"), Array("that", "is", "the", "question-"), Array("William", "Shakespeare"))
val transformed = tokenize(spark.sparkContext.parallelize(input))
assert(transformed === expected)
}
Now, you should expect that the test case will be failed. Now run the earlier class as ScalaTest-File (Figure 12):
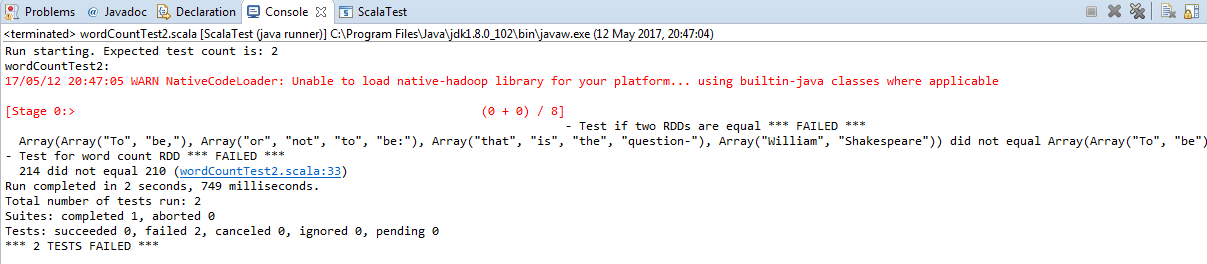
Well done! We have learned how to perform the unit testing using Scala's FunSuite. However, if you evaluate the preceding method carefully, you should agree that there are several disadvantages. For example, you need to ensure an explicit management of SparkContext creation and destruction. As a developer or programmer, you have to write more lines of code for testing a sample method. Sometimes, code duplication occurs as the Before and the After step has to be repeated in all test suites. However, this is debatable since the common code could be put in a common trait.
Now the question is how could we improve our experience? My recommendation is using the Spark testing base to make life easier and more straightforward. We will discuss how we could perform the unit testing the Spark testing base.