
Let's start with loading, parsing, and viewing simple flight data. At first, download the NY flights dataset as a CSV from https://s3-us-west-2.amazonaws.com/sparkr-data/nycflights13.csv. Now let's load and parse the dataset using read.csv() API of R:
#Creating R data frame
dataPath<- "C:/Exp/nycflights13.csv"
df<- read.csv(file = dataPath, header = T, sep =",")
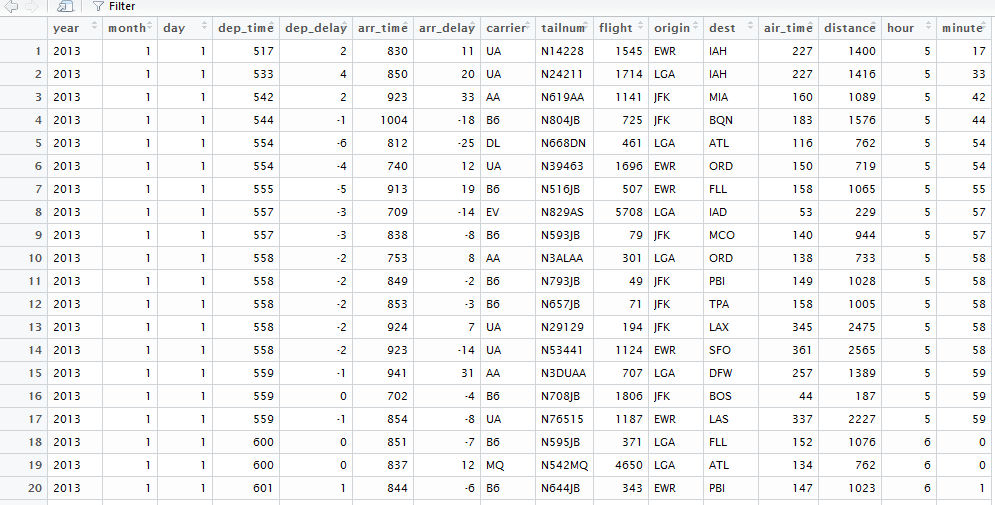
Now let's view the structure of the dataset using View() method of R as follows:
View(df)
Now let's create the Spark DataFrame from the R DataFrame as follows:
##Converting Spark DataFrame
flightDF<- as.DataFrame(df)
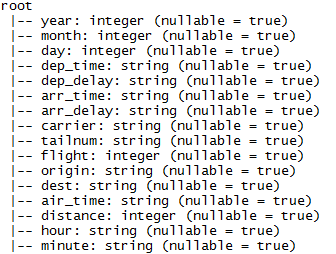
Let's see the structure by exploring the schema of the DataFrame:
printSchema(flightDF)
The output is as follows:
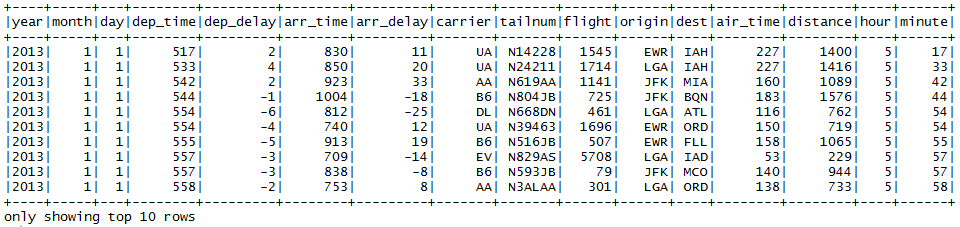
Now let's see the first 10 rows of the DataFrame:
showDF(flightDF, numRows = 10)
The output is as follows:
So, you can see the same structure. However, this is not scalable since we loaded the CSV file using standard R API. To make it faster and scalable, like in Scala, we can use external data source APIs.