
We have already learned some important features of Splunk, creating analytics and visualizations, along with various dashboard customization techniques. Now we will learn about various ways we can tweak Splunk so that we can get the most out of it and that to efficiently. In this chapter we will learn various management and customization techniques for using Splunk in the best possible way.
In this chapter, we will cover the following topics in detail, along with example and uses.
- Index replication
- Indexer auto-discovery
- Sourcetype manager
- Field extractor
- Search history
- Event pattern detection
- Data acceleration
- Splunk buckets
- Search optimizations
- Splunk health
Splunk supports a distributed environment. Now, when it is said that Splunk supports a distributed environment, what does this actually mean? What is the use of Splunk being deployed in a distributed environment?
Splunk can be deployed in a standalone environment and in a distributed environment as well. Let us understand what a standalone environment, a distributed environment, and index replication are.
In a standalone environment, various components of Splunk, like the indexer or search head are available on a single machine, which handles everything from on-boarding data on Splunk, indexing the data, analytics and visualization, reporting, and so on. Generally, standalone is used for development and testing purposes; it is not at all recommended for deployment scenarios.
In a distributed environment, various components of Splunk (the indexer, search head, and others) are deployed in clusters. Deploying in a clustered environment helps to produce multiple copies of the same data for high availability and reduces the chances of data loss in case of hardware failures and disaster recovery.
Splunk is a big data log monitoring and analytics tool, which is the reason why Splunk should be deployed in a distributed environment. It helps in achieving real-time analytics on a Splunk distributed environment. So let us have a look at some of the terminologies of distributed components, which we will be using to understand a distributed deployment of Splunk:
- Clusters: Clusters are groups of Splunk indexers configured to replicate each other's data so as to have multiple redundant copies of all the data.
- Master node: Master node, also known as the cluster master, has the responsibility of managing the cluster. It is recommended to have one master node for one cluster. In Splunk architecture, the master node is shown using the following symbol:

- Peer nodes: Peer nodes are sets of indexers where the actual data gets indexed and is stored. There can be several indexers depending upon the replication factor to store multiple copies of all the data. The following image depicts the symbol for the peer node:

- Replication factor: This factor determines the number of copies of data that should be available in a cluster and thus, the replication factor can be said to be the fundamental level of a cluster's failure tolerance. The following image shows replication, with each box representing an individual replicated peer node of a cluster:

- Search heads: Search heads are responsible for managing and coordinating searching over peer nodes on the basis of the search factor. A search head is shown in the architecture of Splunk using the following depiction:

- Search factor: The search factor defines the number of searchable copies of data that should be available in a cluster. This factor can be used to understand the capability of a cluster to be able to recover its searching capability after any peer node's failure.
Now let us understand how searching actually happens in a distributed environment of Splunk, and some important scenarios.
The following image describes a single cluster of a Splunk distributed environment with the replication factor as three. As seen in the image, there are three peer nodes:
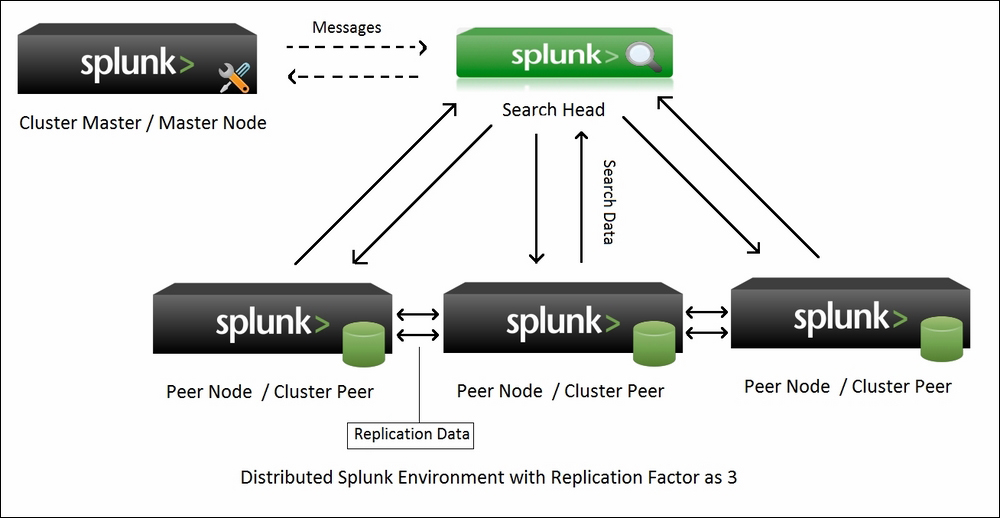
There are three types of communication in the preceding distributed cluster image.
- Messages: The cluster master communicates a list of peer nodes/cluster peers to the search head. The search head is always communicated with the list of peer nodes for searching.
- Search data: The search head distributes search queries to a peer node / cluster peer for search processing and then consolidates the result.
- Replication data: The peer node communicates with other peer nodes / cluster peers to keep all the nodes with an updated copy of all the data among each other.
How Splunk's distributed environment manages itself in case of failures to avoid performance issues and data loss is as follows:
- Peer node / cluster peer fails: Let us suppose we have a cluster similar to the one in the preceding example image. If any of the peer nodes fail or go down, the following is the mechanism performed by the various components of a Splunk distributed environment:
- The cluster master, which always keeps track of peer nodes detects the peer is down. It instructs another working node to act as a primary peer node.
- The cluster master now instructs the search head to use the redundant peer node for replication so as to meet the replication factor defined. Hence, a peer node, which is just kept for future use, is used and a full data replication starts on the new disk.
- Cluster master fails: If the cluster master, which gives commands to the search head itself goes down, then the following is the working flow of the cluster:
- The search head continues to run its normal functioning as per the list of search peer nodes last updated by the cluster manager.
- The newly arrived data may or may not have enough replicated copies, as the cluster master is not available to maintain compliance of the replication factor.
- Once the cluster master is back, it updates the search head and also starts replication for any unreplicated copies (if applicable) since its failure.
The Splunk Web console provides information regarding where the distributed environment can be found. In the Splunk Web console, click on Settings | Distributed Management Console. Using the distributed management console, various important information an be attained, like the number of available peer nodes, indexers for the given cluster, and from those, how many are searchable and how many are down. This section also gives information about the indexing rate, the amount of disk and license used, the number of searches and their types, and the system health status.
Thus, index replication should be used actively, using distributed Splunk deployment so as to avoid data loss in case of failures and for business continuity of real-time analytics and visualizations.