
Splunk 6.3 introduced a very usable and important feature for distributed environments. This feature simplifies forwarder management, which automatically detects new peer nodes in a cluster, and thus, load balancing is handled by itself.
Let us understand the use of indexer auto-discovery using the following cluster example image. The following image shows forwarders sending data to peer nodes. The peer node list and other relevant messages are being communicated from the cluster master to the forwarders:
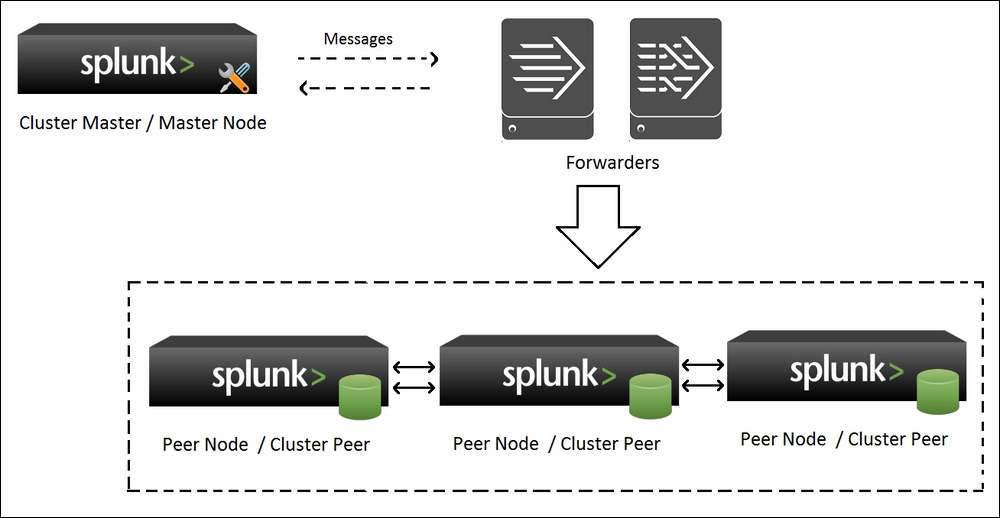
The following are the uses/advantages of indexer auto-discovery:
- There is no need for configuration on forwarders specifying the number of peer nodes in the given cluster. The forwarder is automatically informed with the updated list of peer nodes by the master. Thus, when a peer node fails or new peer nodes are added in a cluster, there is no configuration requirement on forwarders.
- There is no need to know the number of peer nodes when adding or removing a forwarder. Indexer auto-discovery needs to be enabled for a newly added forwarder and the cluster master takes care of the rest.
- The cluster master will be able to know the total disk space on each peer node, which can help to maintain load balancing. This information is communicated to forwarders and then the forwarders adjust the data sent to each of the peer nodes according to the disk space.
Now let us have a look at how to enable and configure indexer auto-discovery in Splunk Enterprise:
- The peer nodes are to be configured to receive and index data from forwarders:
- This can be enabled from the Splunk Web console | Settings | Data | Forwarding and Receiving. In the Settings page, under section Receive Data, a new port number to receive data from forwarders can be configured.
- Receiving can also be enabled by configuring the receiving port in the
inputs.conffile.
- Enabling indexer auto-discovery on the cluster master node can be done by configuring the
server.confconfiguration file on the master node.The following is a sample configuration to enable indexer auto-discovery on the master cluster:
[indexer_discovery] pass4SymmKey = "Security_key" polling_rate = Number_btw_1_10 indexerWeightByDiskCapacity = true/false
The parameters used in the preceding snippet are discussed in the list that follows:
Security_key: It is a string which will be used to authenticate the cluster master and forwarders to enable secure communication.polling_rate: It is the rate at which the forwarder polls the cluster master for the list of peer nodes. It can be defined as any integer value between 1 and 10.indexerWeightByDiskCapacity: If set totrue, the cluster master fetches the disk capacity of all the peer nodes and communicates it to the forwarders for weighted load balancing.
- Now, since the indexer auto-discovery is configured in the cluster master, forwarders are to be configured for index auto-discovery. The following is a sample configuration which needs to be configured in the
outputs.conffile of every forwarder in the cluster to enable auto-discovery:[indexer_discovery: Name_Index_Discovery] pass4SymmKey = "Security_key" master_uri = Master_Node_URI_with_Port [tcpout: Group_Name] indexerDiscovery = Name_Index_Discovery useACK=true
The parameters used in the preceding snippet are discussed in the list that follows:
- A unique string (
Name_Index_Discovery) which we will be using inindexerDiscoveryoftcpoutto identify the cluster master. This is useful in case more than one cluster has indexer auto-discovery enabled. Security_keyis the same as that which is configured in the cluster master for authentication.Master_Node_URI_with_Portis the URI along with the management port of the cluster master from which the list of peer nodes is to be fetched.Group_Nameis a unique name to define index discovery and acknowledge options. Any string can be defined asGroup_Name, as per the user.useACK=trueis an optional parameter; if defined and set totrue, it enables indexer acknowledgement.
- A unique string (
Thus, indexer auto-discovery should be enabled in a distributed environment of Splunk Enterprise so as to avoid reconfiguration and management of forwarders whenever there is any change in clusters or forwarders.