
Splunk is a big data tool and hence, it is obvious that the reports and dashboards created on Splunk will have large datasets/events. So data acceleration is very much necessary to get real-time analytics and visualizations.
Let's understand the need for data acceleration in reports and dashboards with the help of the following image. The following image is an example screenshot of a dashboard with many panels and thus, many searches. When there are many searches running concurrently in a report/dashboard then it takes time to show the analytics or visualization on the dashboard. Thus for real-time analytics, data acceleration will be required:
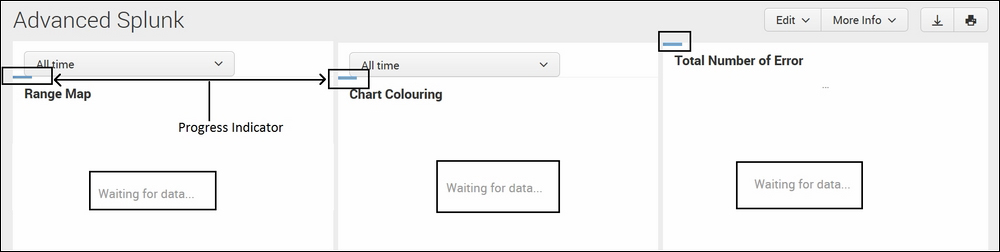
Splunk is a very powerful big data tool, so why does it takes time to populate the results on the dashboard/report? The reason behind why some searches complete quickly and some take too much time can be explained with the help of the following facts:
- Splunk is very fast at finding a keyword or set of keywords from millions of events.
For example, searching
error=404among millions of events. - Splunk is not fast at searches having calculations on millions of events.
For example, calculation of any mathematical formula, count, mean, median, and so on, on millions of events.
Hence, which kinds of searches should be included in the reports/dashboard can be decided by taking into account the preceding facts to get real-time analytics.
Let us understand how we can implement data model acceleration (also known as persistent data model acceleration) so as to speed up the data processing and data searching to give real-time analytics. Data model acceleration is an inbuilt tool in Splunk which adds a second layer to the data to increase the speed of a Splunk search on large datasets with millions of events in real time. Data model acceleration does not remove any functionality from Splunk basic searches but creates a schema of pre-defined fields:
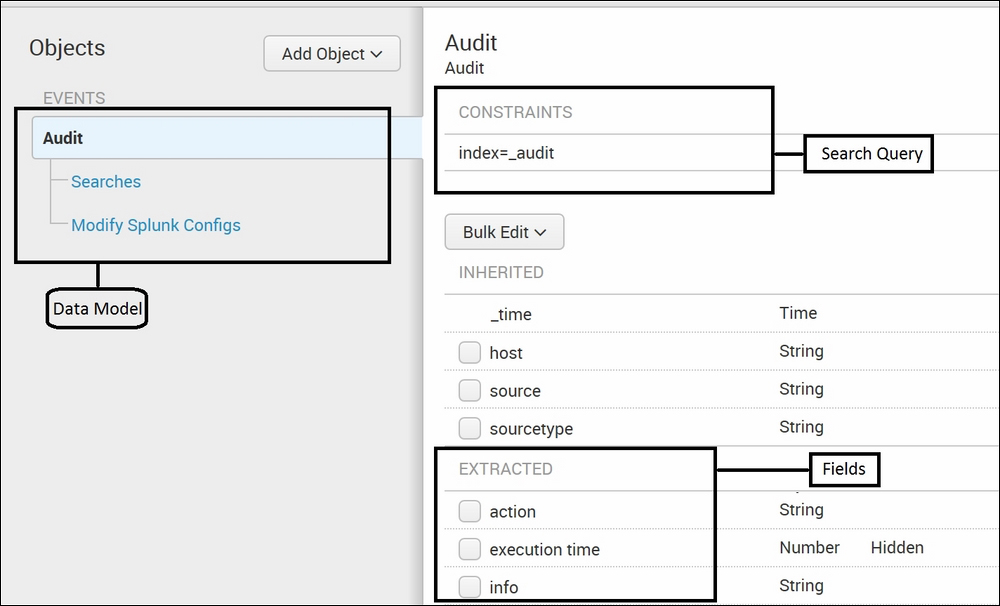
The preceding image is a snapshot of Splunk's inbuilt data model of the Audit index. The data model helps to create instant pivot charts as well as helping acceleration reports to get faster results. The data model is hierarchical in that at each hierarchy level, fields are extracted and kept ready for use for the next level in the hierarchy and so on.
Generally, in normal scenarios, the fields are extracted from the raw data during the search time, but when data model acceleration is enabled, the field extraction process happens during index time. So, search performance is optimized, as the fields are already extracted and available during searching, but this adds overhead during indexing and thus higher indexer utilization happens when data model acceleration is enabled. The extracted data model fields are stored in the High
Performance Analytics Store (HPAS), available on indexers as .tsidx files.
The data model can also be accelerated as shown in the following image. The option to accelerate the data model as shown in the following image can be accessed from the Splunk Web console by navigating to Data Model | Edit | Edit Acceleration:
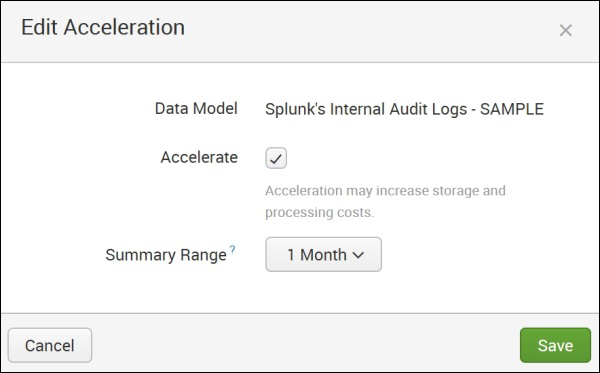
The following are the few limitations of data model acceleration:
- Only data model event hierarchy is accelerated
- Once the acceleration is enabled on the data model, it cannot be edited
Data model acceleration has been available in older versions of Splunk as well. In Splunk 6.3, which features an additional technique, parallelization, already learned earlier, helps in running two concurrent search jobs instead of one. Thus, more efficient and faster accelerations are possible as compared to older versions of Splunk. The data acceleration is due to the use of exclusive HPAS during the pivot and while using the tstat command.
Let us see how to check the status of data model acceleration from the Splunk Web console.
Navigate from the Splunk Web console to Settings | Data Models. The following image shows the sample of data model acceleration status:
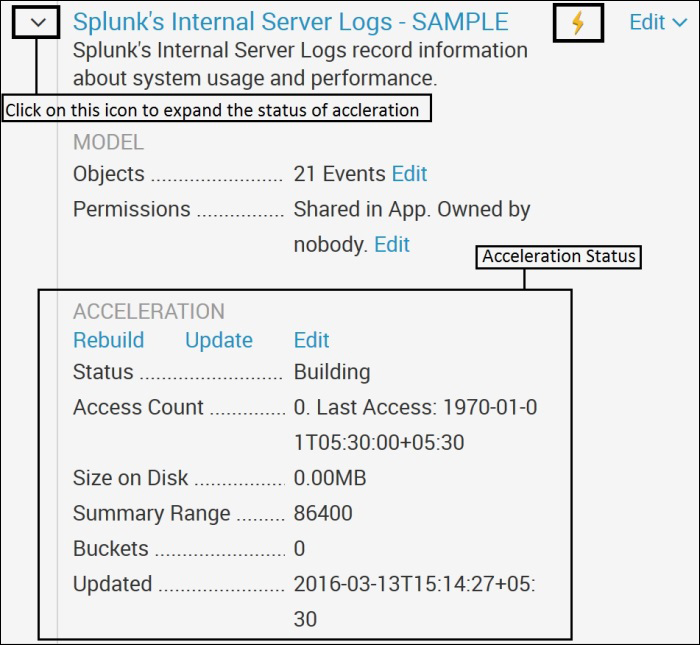
The data model's definition is stored in the respective model's folder or respective app directory $SPLUNK_HOMEetcappsappnamedefaultdatamodels in JSON format (modelname.json). The definition of the data model (JSON file) is stored on the search head.
Apart from persistent data model acceleration, which we have just studied, Splunk also has the capability to run ad hoc data model acceleration. The following is the scenario when Splunk automatically implements ad hoc data model acceleration: