
The Results set of commands is used to manage the output of the search results. This set of commands can be used to filter the events, reformat the events, group them, reorder them, and read and write on the results.
The fields command is used to keep (+) or remove (-) fields from the search results. If + is used, then only the field list followed by + will be displayed, and if – is used, then the field list followed by – will be removed from the current result set.
The syntax for the fields command is as follows:
… | fields +/- field_list
Refer to the following example for better clarity:
index=_internal | top component cumulative_hits executes | fields – percent
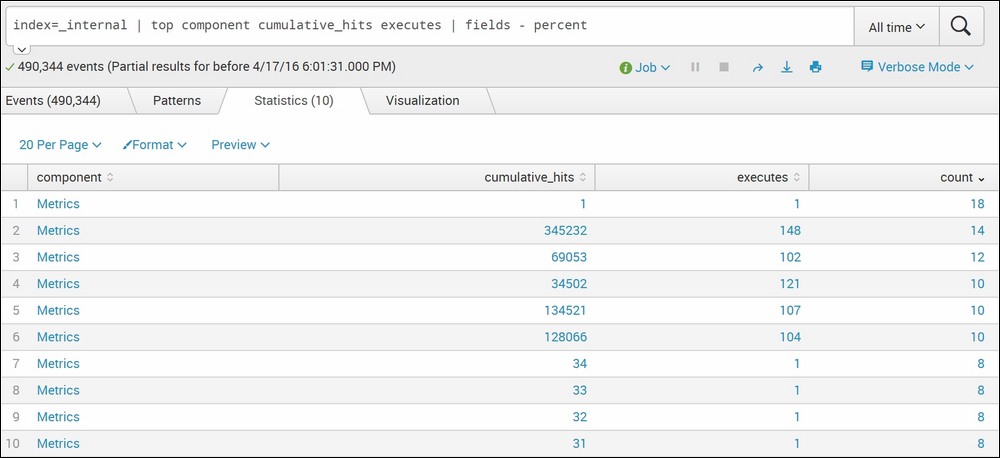
In the preceding screenshot, we have used the top command. The top command returns the count and percentage of the specified fields. So, we have used fields – percent, which shows all the fields, except percent. Similarly, the fields command can be used to get the desired output.
The
searchtxn command of Splunk is a useful command to get events that match the specific text and transaction type. This command can be used to find a transaction that satisfies a certain set of conditions. Let's say the user is interested in finding out all the login failed attempts due to an incorrect password. In this case, the searchtxn command can be used.
The syntax for the searchtxn command is as follows:
| searchtxn transaction-name search_query
Refer to the following for parameter descriptions:
transaction-name: Name of the transaction as defined in thetransactiontypes.conffilesearch_query: The search string for which the transactions are needed
Refer to the following example for better clarity:
| searchtxn webmaillogin="failed"login_error="Password Incorrect"
The preceding query will return all the search transactions of the webmail that has login as failed and a login error as Password Incorrect.
The
head Splunk command is used to fetch the first n number of specified results, and the tail command is used to fetch the last n number of specified results from the result set.
The syntax for the commands is as follows:
… | head n | Expression … | tail n
The parameter description for the preceding query is as follows:
The example of the head…tail commands is mentioned with the explanation, as follows:
… | head 10 … | tail 10
In the preceding search query, the head 10 will list out first 10 events, and the tail 10 will return the last 10 events in the search results.
The
inputcsv command of Splunk is a generating command and can be used to load search results directly from the specified .csv file located in $SPLUNK_HOME/var/run/splunk. The inputcsv command does not upload the data on Splunk; it fetches it directly from the .csv file and loads the result.
Following is the syntax for the inputcsv command:
|inputcsv dispatch=true / false append=true / false events=true / false filename
A parameter description of the preceding query is as follows:
dispatch: If thedispatchparameter is set totrue, then Splunk looks for the.csvfile in thedispatchdirectory, that is,$SPLUNK_HOME/var/run/splunk/dispatch/<job id>/. The default value for thedispatchparameter isfalse.append: Theappendparameter, if set totrue, appends the data from the.csvfile to the current result set. The default value for this parameter isfalse.events: If theeventsparameter is set totrue, then the content loaded from the.csvfile is available as events in Splunk where timeline, fields, and so on will be visible as if the file is uploaded on Splunk. Generally, for the CSV file to get loaded as events, a timestamp is required in the file.filename: The name of the CSV file. Splunk first searches for the filename. If it does not exist, it searches for the.csvfilename. So, this means if the file exists but does not have a.csvextension, that file will still get loaded using theinputcsvcommand.
An inputcsv query looks like the one shown following:
|inputcsv TestCSV
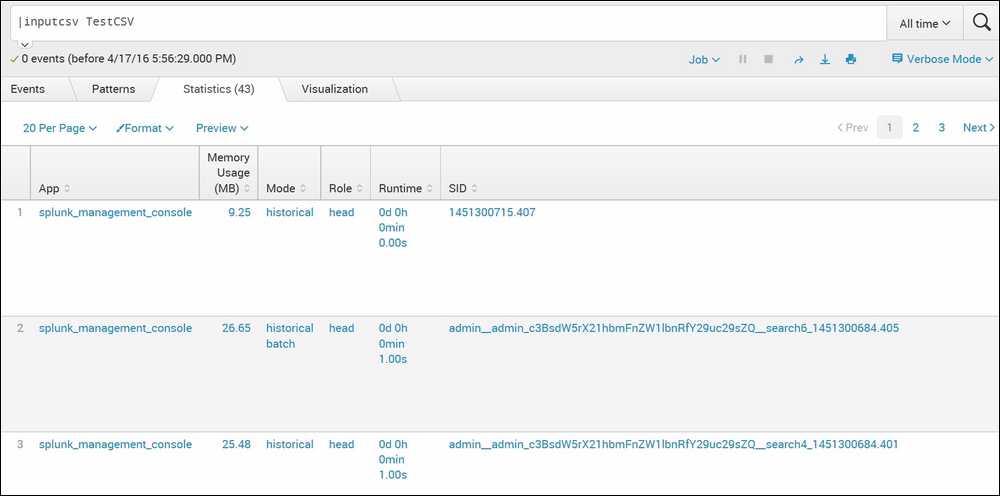
As shown in the preceding screenshot, the TestCSV file gets loaded into Splunk using the inputcsv command from $SPLUNK_HOME/var/run/splunk as the dispatch parameter is not set and by default it is false.
The outputcsv command of Splunk works exactly opposite to the inputcsv command. This command exports the results into a .csv file at $SPLUNK_HOME/var/run/splunk.
The syntax for the outputcsv command is as follows:
Outputcsv append=true / false create_empty=true / false dispatch=true / false singlefile=true / false filename
The parameter description for the ouputcsv command is as follows:
append: Ifappendis set totrue, then the results are appended to the file if it exists or a new file is created. If there is a pre-existing file and it has headers, then headers are omitted during appending. The default value for this parameter isfalse.create_empty: In a scenario when there is no result and this parameter is set totrue, then Splunk creates an empty file with the name specified. Ifappendandcreate_emptyare set tofalseand there is no result, then in this case, any pre-existing files will be deleted.dispatch: If set totrue, then the output will be saved in thedispatchdirectory, that is,$SPLUNK_HOME/var/run/splunk/dispatch/<job id>/.singlefile: If this parameter is set totrueand the result is in multiple files, then Splunk collapses the output in one single file.filename: Name of the file in which the result is to be stored.
Refer to the following example of the outputcsv command:
index=_internal | top component cumulative_hits | outputcsv ResultCSV
The preceding Splunk query will output the result of the query in to a filename, ResultCSV, which will be stored at $SPLUNK_HOME/var/run/splunk.