
We have already learned data acceleration and the bucket life cycle in the preceding section. Let us now see how we can make the best use of search queries for better and more efficient results. Splunk search queries can be optimized depending upon the requirements and conditions. Generally, the search queries which need to be optimized are those which are used most frequently. Let us learn a few tricks to optimize the search for faster results.
We have already learned about Splunk buckets, which organize events based on time. The shorter the time span, the less buckets will be accessed to get the information of the search result. It has always been a common practice to use All time in the time range picker for any search, irrespective of whether the result is required for all of the duration or some limited duration.
So one of the best search optimization methods is to use the time range picker to specify the time domain on which the search should run to get the result. Since the time limit will be specified, only limited buckets will be accessed, irrespective of all the buckets and thus, faster and more optimized results will be obtained.
Splunk has three search modes: verbose, fast, and smart. These modes are discussed as follows:
- The verbose mode is the slowest and most exploratory option, which returns as much events information as possible.
- The smart mode, depending upon the
searchcommand used in the search query, sometimes behaves like the fast mode and sometimes like the verbose mode. - In the fast mode, field discovery is switched off and it is the fastest of all the modes. Dashboards and reports use the fast mode by default.
If the searches are done in the fast mode, the search results can be obtained three to five times faster than in the verbose mode.
In Splunk, to access data we have index, source, and sourcetype. Index helps in locating the disk from which the data will be read. Source and sourcetype should be used to specify exactly where to look for data. Specifying the scope can result in up to 10 times faster results than not using the scope.
Let me explain the use of the scope and how can it accelerate the result of a search query using an example:
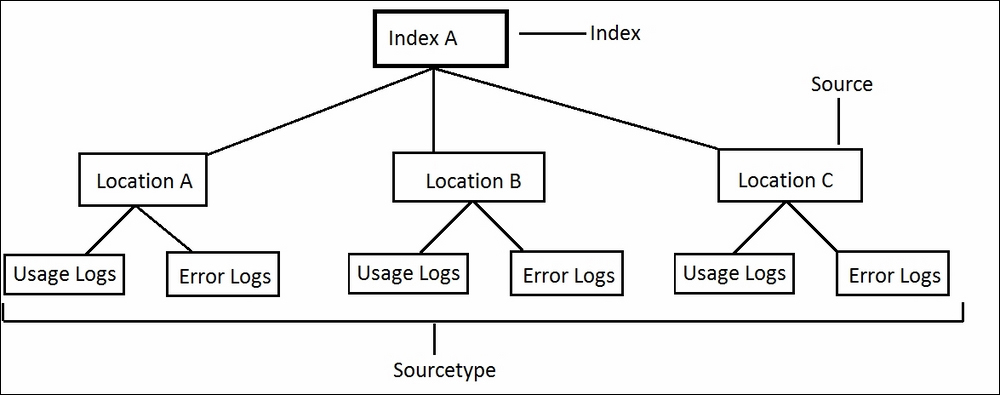
In the preceding example image, we have one index (Index A), three sources (Location A, Location B, and Location C) and two sourcetypes (Usage Logs and Error Logs):
- Now let us suppose if the result is required for only the usage logs of all the sources (locations), then the search query should be as follows:
Index= "indexA" sourcetype= "usage_logs" - If
usage_logsof only Location A are required, then the source should be as follows:Index= "indexA" source= "locationA" sourcetype= "usage_logs"
Similarly, only the data should be searched for which the result is required and hence, since the amount of unnecessary data searching is removed by using scope (index, source, and sourcetype) the search will be efficient and faster.
When specifying the scope of searching using index, source, and sourcetype, the following precautions should be taken to accelerate the search results:
- Avoid using the following search:
Index= "abc" foo | search barInstead, the preceding search query should be
Index= "abc" foo bar. - Avoid using
NOTas far as possible:Index= "abc" sourcetype= "errorlogs" NOT error=404The preceding search query should be reformatted for faster processing as:
Index= "abc" sourcetype= "errorlogs" AND (error=400 OR error=401 OR error=403) - Combine multiple instances of
renameandrextogether:… | rename A as "I am A" | rename B as "I am B"The preceding search query has two instances of
rename; those two should be combined as shown in the following. It should be noted thatrenameshould always be added at the end:… | rename A as "I am A", B as "I am B" - Fields should be used before
stats, fortablecommand preferably, as shown in the following:Index= "webserverlogs" | stats count by error | search error=404The preceding search query should be replaced by the following query for faster processing:
Index= "webserverlogs" error=404 | stats count by error - Subsearches (
append) should be avoided for faster processing. The following example shows how an append can be avoided. Subsearches should strictly not be used for real-time searches:Index= "locationA" | eval variable=locA | append [search index= "locationB" | eval variable=locB]The preceding search query can be replaced by the following for faster and more efficient performance:
Index= "locationA" OR index= "locationB" | eval variable=case (index== "locationA", "locA", index== "locationB", "locB") - Use
renameinstead ofevalwherever possible. Usingrenameinstead ofevaldoesn't make any difference in results, but it has been observed thatrenameis faster thanevalsometimes:… | eval abc= "This is test statement"The preceding
evalstatement can also be written as follows:… | rename abc as "This is test statement"
Thus by making efficient use of Splunk search queries, it can be optimized for accurate and faster results.