
DISCOVERING JET OPTIMIZATION METHODS
The following sections cover some of the optimization methods that the Jet database engine applies during the optimization porting of the query resolution process. This includes taking advantage of Rushmore technology, paying attention to when to use indexes, and understanding how Jet optimizes queries.
Using Rushmore Technology
Rushmore technology is a query technology that takes advantage of indexes. First introduced in FoxPro 2 by Fox Software, its creator got its name from the movie North by Northwest (how's that for trivia?). Access 2 inherited some of the Rushmore technology, and you can greatly increase performance by taking advantage of it.
Rushmore technology involves using the indexes on tables to solve WHERE clauses in SQL statements. Rushmore takes advantage of multiple indexes on a table and takes effect when the WHERE clause references multiple indexed fields. To understand how this works, let's take a quick look at the index structure in Microsoft Access.
When you add an index to an Access table, you're essentially running a Make Table query (Make Index, in this case), which creates a miniature version of the table with a pointer back to the main record. In this case, the pointer isn't the primary key but instead is a bookmark or internal pointer that contains the information to locate and retrieve the main record quickly. Each index contains an entry for every record in the original table. Figure 8.40 shows an example of how indexes work internally.
Figure 8.40. This is how indexes look under the covers, with pointers to specific records.
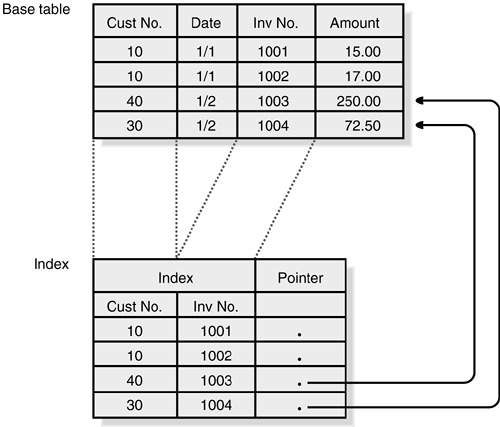
Rather than use one index to limit the record search and resolve the rest of the WHERE clause by looking at each record, Rushmore looks at multiple indexes and applies part of the criteria to the appropriate indexes. When a list of the matching bookmarks is obtained from a single index, the bookmarks are compared with the bookmarks from other index searches. The bookmarks are unioned (or) or joined (and) to get a resulting list of bookmarks that you can use to retrieve the actual data records. If the result of the query is a count and the field you're counting on is in the index, the query will perform the count on the index rather than retrieve actual records from the table.
Rushmore also applies when compound indexes are present and contain fields used in the queries. The restriction here is that the fields in your criteria must be included as the first fields, not the last fields, in the index.
Examining the Clustered Primary Index
Microsoft Access stores records in tables in the order that they're entered into the system. Creating indexes and relationships for tables doesn't affect the order of the data in the table in most cases. However, during a repair and compact operation, Access reorders the records in a table to put them in primary index order. Depending on how you use data from a table, this could be a significant advantage because data within a range of values will be stored near other data with the same values.
The following is an example of a customer invoice table, showing the data at the end of a day of sales on January 2. Typically, data is entered randomly for customers as they call with new orders and are invoiced for the cost of the materials they purchase.
| Record | Cust | Invoice | Date | Amt |
|---|---|---|---|---|
| 1 | 010 | 1020 | 1/1 | $153.00 |
| 2 | 100 | 1022 | 1/1 | $760.00 |
| 3 | 219 | 1023 | 1/1 | $210.00 |
| 4 | 430 | 1021 | 1/1 | $120.00 |
| 5 | 100 | 1024 | 1/2 | $150.00 |
| 6 | 430 | 1025 | 1/2 | $550.00 |
| 7 | 010 | 1026 | 1/2 | $286.00 |
| 8 | 219 | 1027 | 1/2 | $110.00 |
Most often, this table locates the amount of a specific invoice or determines the total of unpaid invoices for a customer. An index on Customer,Invoice would allow quick access to the records in the table but would require jumping around in the table to get all the information for one customer. For example, retrieving customer 010 would require records 1 and 7, which aren't next to each other in the table. In a system with thousands of records, the records could be quite far apart, requiring that pages be retrieved in very different areas of the database and, thus, slowing the performance.
Generally, you would choose to make the invoice number a primary key on this table because it's a non-null unique key. In this case, you can increase performance by making the primary key on Customer,Invoice and creating a unique index on the invoice number. After a repair and compact, the actual records in the table are reordered by customer:
| Record | Cust | Invoice | Date | Amt |
|---|---|---|---|---|
| 1 | 010 | 1020 | 1/1 | $153.00 |
| 2 | 010 | 1026 | 1/2 | $286.00 |
| 3 | 100 | 1022 | 1/1 | $760.00 |
| 4 | 100 | 1024 | 1/2 | $150.00 |
| 5 | 219 | 1023 | 1/1 | $210.00 |
| 6 | 219 | 1027 | 1/2 | $110.00 |
| 7 | 430 | 1021 | 1/1 | $120.00 |
| 8 | 430 | 1025 | 1/2 | $550.00 |
Because the data is now closer together for a given customer, the caching that takes place when the first record is retrieved for a customer will move several of the records for the customer into memory. Access won't need to go back to the disk to retrieve the second record for the customer.
Note
If you're wondering why the invoice number is included in the primary key when it isn't required to accomplish the clustering goal, keep in mind that a primary key must be unique. In this situation, the combination of fields is needed to ensure uniqueness in the primary key. In the example, the invoice number is an AutoNumber field and is unique for all records.
Before implementing this technique, you should understand its disadvantages. Most important is that the database must be repaired and compacted for the records to be reordered. This needs to occur on a regular basis to take full advantage of the clustering. As new records are added to the table, they're still added at the end of the table in the order they were entered. The customer data in the example becomes fragmented at the end of the table each day; after several hundred records are added, performance can begin to drop off again.
The other disadvantage is that the primary key no longer represents the real primary key for the table. The primary key in terms of the database schema is still the invoice number. This can be misleading when others look at the database, so it's best to include notes about this type of optimization in the system documentation.
Finally, this clustering might actually slow down some of the other queries run against the table. If you have a report that creates a sales analysis listing the total sales for each day and month-to-date, it might begin to run more slowly because now the data is ordered by customer rather than by date. When the data was in invoice number order, it was very close to date order. Therefore, as you retrieved a record for a given date, you probably read several other records for the same date into cache. This no longer will happen, so you need to carefully analyze the impact on all your queries before implementing this technique.
Working with Read-Ahead
Jet can't have multiple threads reading or writing at the same time. It can have one thread reading and one thread writing, but threads aren't assigned specific tasks.
Note
Carefully define your tests and measure your results on a machine you have complete control over. Keep in mind that the operating system might do some caching as well. If you're retrieving data from a remote server, make sure that the server load is consistent and that the server is caching the data the same way for each operation.
You can adjust read-ahead settings in the Windows Registry. Refer to the Access help topic “Customize Jet database engine (ISAM) settings” for the current Registry keys and a description of how to change Registry entries. After you determine where you need to make the changes in the Registry, you can alter the thread setting to allow more read-ahead threads. In one application, a 30 percent improvement was gained in the performance of a query by changing this setting from 3 (the default) to 10.
Caution
Be very careful when modifying Registry settings. Make sure that you know what you're doing and have backups.
Note
The thread setting doesn't appear to change the performance of queries that are resolved purely with Rushmore technology, but it does seem to affect queries that must retrieve non-indexed fields from the table data directly.
Using the SetOption Command for Jet's Registry Settings
When using databases with Jet 3.5 and later, you can use the SetOption command, which lets you temporarily override some of Jet's settings. The syntax for the SetOption command is
SetOption parameter, newvalue
where parameter is one of the constants that might be set. Table 8.4 shows the constants available.
| Constant | Description |
|---|---|
| dbExclusiveAsyncDelay | ExclusiveAsyncDelay key |
| dbFlushTransactionTimeout | FlushTransactionTimeout key |
| dbImplicitCommitSync | ImplicitCommitSync key |
| dbLockDelay | LockDelay key |
| dbLockRetry | LockRetry key |
| dbMaxBufferSize | MaxBufferSize key |
| dbMaxLocksPerFile | MaxLocksPerFile key |
| dbPageTimeout | PageTimeout key |
| dbRecycleLVs | RecycleLVs key |
| dbSharedAsyncDelay | SharedAsyncDelay key |
| dbUserCommitSync | UserCommitSync key |
Each constant refers to corresponding Registry keys in the Windows Registry under the path
Hkey_LOCAL_MACHINESOFTWAREMicrosoftJet4.0EnginesJet 4.0
You can see these settings in Figure 8.41. To find them, from the Start menu, choose Run, type regedit, and click OK. Then follow the path just displayed.
Figure 8.41. You can find these settings in the Windows Registry by using Regedit.

By playing with these settings, you can also affect performance, but you'll want to place them in your code at startup because they go away when the version of dbEngine is closed (in other words, when you close your database). They also can be changed by running the SetOption command with the same parameter.
To find out the values to use, you can look up “Initializing the Microsoft Jet 4 Database Engine Driver” in Help.