
Throughout the book you learned, step by step, how to use PDI for accomplishing several kinds of tasks— reading from different kinds of sources, writing back to them, transforming data in several ways, loading data into databases, and even loading a full data mart. You already have the knowledge and the experience to do anything you want or you need with PDI from now on. However, PDI offers you some more features that may be useful for you as well. The following sections will introduce them and will guide you so that you know where to look for in case they want to put them into practice.
As you could see while learning Kettle, there is a large set of steps and job entries to choose from when designing jobs and transformations. The number rises above 200 between steps and entries! If you still feel like you need more, there are more options—plugins.
Kettle plugins are basically steps or job entries that you install separately. The available plugins are listed at http://wiki.pentaho.org/display/EAI/List+of+Available+Pentaho+Data+Integration+Plugins.
Most of the listed plugins can be downloaded and used for free. Some are so popular or useful that they end up becoming standard steps of PDI—for example, the Formula step that you used several times throughout the book.
There are other plugins that come as a trial version and you have to pay to use them.
It's also possible for you to develop your own plugins. The only prerequisite is knowing how to develop code in Java. If you are interested in the subject, you can get more information at http://wiki.pentaho.com/display/EAI/Writing+your+own+Pentaho+Data+Integration+Plug-In.
It's no coincidence that the author of those pages is Jens Bleuel. Jens used the plugin architecture back in 2004, in order to connect Kettle with SAP, when he was working at Proratio. The plugin support was incorporated in Kettle 2.0 and the PRORATIO - SAP Connector, today available as a commercial plugin, was one of the first developed Kettle plugins.
Browse the plugin page and look for a plugin named Head. As described in the page, this plugin is a step that keeps the first x rows of the stream. Download the plugin and install it. The installation process is really straightforward. You have to copy a couple of *.jar files to the libext directory inside the PDI installation folder, add the environment variable for the PDI to find the libraries, and restart Spoon. The downloaded file includes a documentation with full instructions. Once installed, the Head will appear as a new step within the Transformation category of steps as shown here:
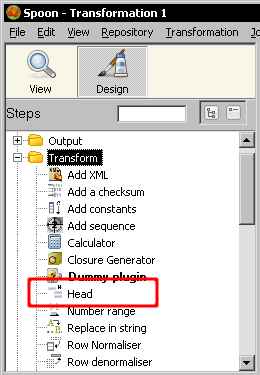
Create a transformation that reads the examination file that was used in the Time for Action - reviewing examination by using the Calculator step section in Chapter 3 and some other chapters as well. Generate an output file with the top 10 students by average score in descending order. In order to keep the top 10, use the Head plugin.
In order to learn to use Kettle, you used very simple and small sets of data. It's worth saying that all you learned can be also applied for processing huge files and databases with millions of records. However, that's not for free! When you deal with such datasets, there are many risks—your transformations slow down, you may run out of memory, and so on.
The first step in trying to overcome those problems is to do some remote execution. Suppose you have to process a huge file located at a remote machine and that the only thing you have to do with that file is to get some statistics such as the maximum, minimum, and average value for a particular piece of data in the file. If you do it in the classic way, the data in the file would travel along the network for being processed by Kettle in your machine, loading the network unnecessarily.
PDI offers you the possibility to execute the tasks remotely. The remote execution capability allows you to run the transformation in the machine where the data resides. Doing so, the only data that would travel through the network will be the calculated data.
This kind of remote execution is done by Carte, a simple server that you can install in a remote machine and that does nothing but run jobs and transformations on demand. Therefore, it is called a slave server. You can start, monitor, and stop the execution of jobs and transformations remotely as depicted here:
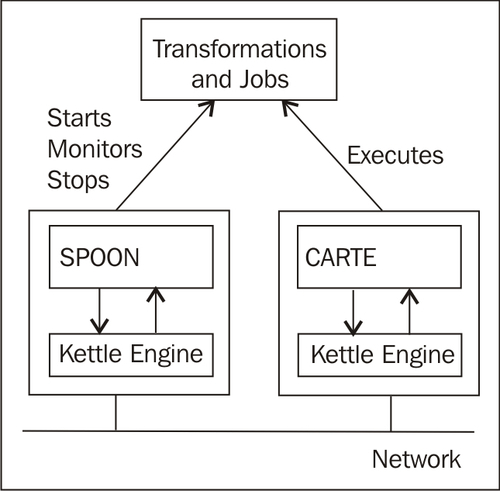
You don't need to download additional software because Carte is distributed as part of the Kettle software. For documentation on carte, follow this link: http://wiki.pentaho.com/display/EAI/Carte+User+Documentation.
As mentioned above, PDI can handle huge volumes of data. However, the bigger the volume or complexity of your tasks, the bigger the risks. The solution not only lies in executing remotely, but in order to enhance your performance and avoid undesirable situations, you'd better increase your power. You basically have two options—you can either scale up or scale out. Scaling up involves buying a better processor, more memory, or disks with more capacity. Scaling out means to provide more processing power by distributing the work over multiple machines.
With PDI you can scale out by executing jobs and transformations in a cluster. A cluster is a group of Carte instances or slave servers that collectively execute a job or a transformation. One of those servers is designed as the master and takes care of controlling the execution across the cluster. Each server executes only a portion of the whole task.
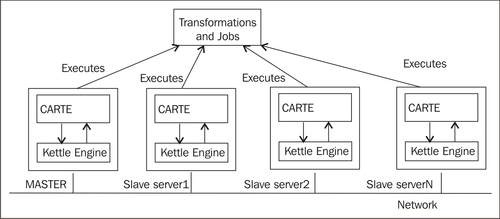
The list of servers that would make up a cluster may be known in advance, or you can have dynamic clusters—clusters where the slave servers are known only at run time. This feature allows you to hire resources—for example, server machines provided as a service over the Internet, and run your jobs and transformations processes over those servers in a dynamic cluster. This kind of Internet service is quite new and is known as cloud-computing, Amazon EC2 being one of the most popular.
If you are interested in the subject, there is an interesting paper named Pentaho Data Integration: Scaling Out Large Data Volume Processing in the Cloud or on Premise, presented by the Pentaho partner Bayon Technologies. You can download it from http://www.bayontechnologies.com.
For each of the following, decide if the sentence is true or false:
a. Carte is a graphical tool for designing jobs and transformations that are going to be run remotely.
b. In order to run a transformation remotely you have to define a cluster.
c. When you have very complex transformations or huge datasets you have to execute in a cluster because PDI doesn’t support that load in a single machine.
d. To run a transformation in a cluster you have to know the list of servers in advance.
e. If you want to run jobs or transformations remotely or in a cluster you need the PDI Enterprise Edition.