
- Open the transformation from the tutorial and save it under a different name.
- From the Transform category, drag the Add constants step to the canvas.
- Create a hop from the Write to log step to the Add constants step.
- Add an
Integerconstant nameddiffwith value999, and aStringconstant namedage_of_filmwith valueunknown. - After the Add constants step, add a Select values step and use it to remove the fields
err_codeanderr_desc. - Create a hop from the Select values step to the Sort rows step. Your transformation should look like this:
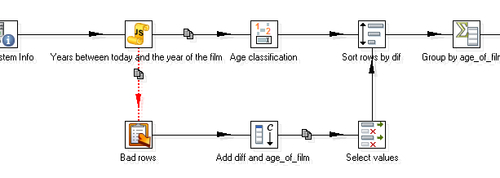
- Select the Dummy step and do a preview. You will see this:
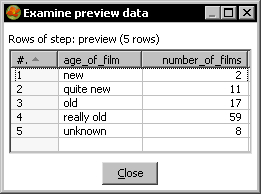
You modified the transformation so that you didn't end up discarding the erroneous rows. In the error stream (the stream after the red dotted line), you fixed the rows by putting default values for the new fields. After that you returned the rows to the main stream.
If the errors are not severe enough to discard the rows, if you can somehow guess what data was supposed to be there instead of the error, or if you have default values for erroneous data, you can do your best to fix the errors and send the rows back to the main stream.
What you did instead of discarding the rows with no year information was to fix the rows and send them back to the main stream. The Group by step grouped them under a separate category named unknown.
There are no rules for what to do with bad rows where you handle errors. You always have the option to discard the bad rows or try to fix them. Sometimes you can fix only a few and discard the rest of them. It always depends on your particular data or business rules.
What does the PDI error-handling functionality do:
a. Avoids the happening of unexpected errors
b. Captures errors that happen and discards erroneous rows so you can continue working with valid data
c. Captures errors that happen and sends erroneous rows to a new stream, letting you decide what to do with them
On the Packt website you will find a modified football match file named wcup_modified.txt. This modified file has some intentional errors.
Download the file and do the following:
- Create a transformation, read the file with a Text file input step. Set all fields as string.
- Add a JavaScript step and type the following code in it:
var result_desc; result_split = Result.split('-'), home_g = str2num(result_split[0]); away_g = str2num(result_split[1]); if (home_g > away_g) result_desc = Home_Team + ' wins'; else if (home_g < away_g) result_desc = Away_Team + ' wins'; else result_desc = 'Nobody wins'; - In the grid below the code, add the string variable
result_desc. - Do a preview on the JavaScript step and see what happens.
- Now try any of the following two solutions:
- Handle the errors and discard the rows that cause those errors. Abort if there are more than 10 errors.
- Handle the errors and fix the transformation by setting a default result description for the rows that cause the errors.