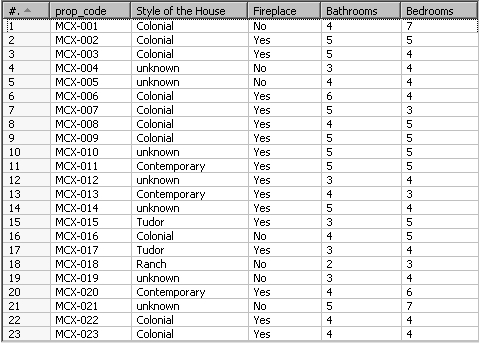
In this tutorial we will work with a file that contains list of all French movies ever made. Each movie is described through several rows. This is how it looks like:
... Caché Year: 2005 Director:Michael Haneke Cast: Daniel Auteuil, Juliette Binoche, Maurice Bénichou Jean de Florette Year: 1986 Genre: Historical drama Director: Claude Berri Produced by: Pierre Grunstein Cast: Yves Montand, Gérard Depardieu, Daniel Auteuil Le Ballon rouge Year: 1956 Genre: Fantasy | Comedy | Drama ...
In order to process the information of the file, it would be better if the rows belonging to each movie were merged into a single row. Let's work on that.
- Download the file from the Packt website.
- Create a transformation and read the file with a Text file input step.
- In the Content tab of the Text file input step put
:as separator. Also uncheck the Header and the No empty rows options. - In the Fields tab enter two string fields—
featureanddescription. Do a preview of the input file to see if it is well configured. You should see two columns—featurewith the texts to the left of the semicolons, anddescriptionwith the text to the right of the semicolons. - Add a JavaScript step and type the following code that will create the
filmfield:var film; if (getProcessCount('r') == 1) film = ''; if (feature == null) film = ''; else if (film == '') film = feature; - Click on the Get variables button to add to the dataset the field
film. - Add a Filter rows step with the condition
description IS NOT NULL. - With the Filter rows step selected, do a preview. This is what you should see:
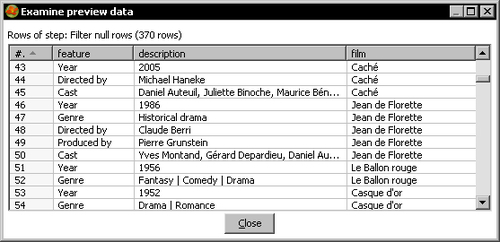
- After the filter step, add a Row denormalizer step. You can find it under the Transform category.
- Double-click the step and fill it like here:
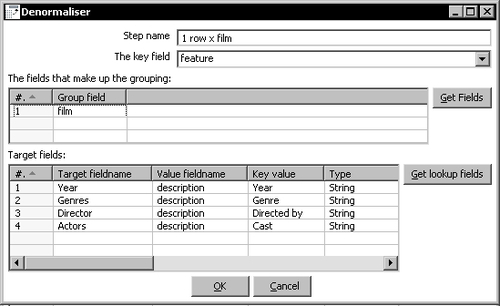
- From the Utility category select an If field value is null step.
- Double-click it , check the Select fields option, and fill the Fields grid as follows:
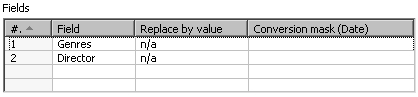
- With this last step selected, do a preview. You will see this:
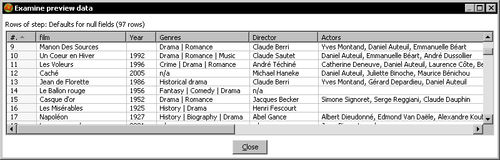
You read a file with a selection of films in which each film was described through several rows.
First of all, you created a new field with the name of the film by using a small piece of JavaScript code. If you look at the code, you will note that the empty rows are key for calculating the new field. They are used in order to distinguish between one film and the next and that is the reason for unchecking the No empty rows option. When the code executes for an empty row, it sets the film to an empty value. Then, when it executes for the first line of a film (film == ' ' in the code), it sets the new value for the film field. When the code executes for other lines, it does nothing but the film already has the right value.
After that, you used a Row denormalizer step to translate the description of films from rows to columns, so the final dataset had a single row by film.
Finally, you used a new step to replace some null fields with the text n/a.
The Row denormaliser step converts the incoming dataset into a new dataset by moving information from rows to columns according to the values of a key field.
To understand how the Row denormaliser works, let's do a sketch of the desired final dataset:
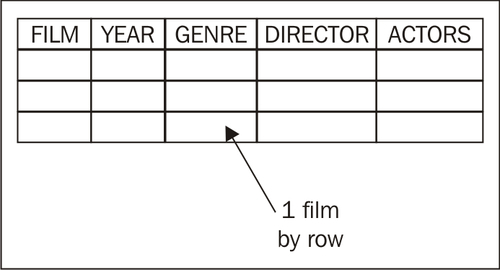
Here, a film is described by using a single row. On the contrary, in your input file the description for every film was spread over several rows.
To tell PDI how to combine a group of rows into a single one, there are three things you have to think about:
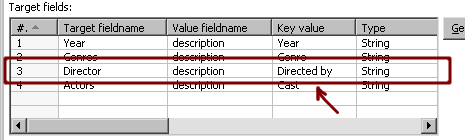
- Among the input fields there must be a key field. Depending on the value of that key field, you decide how the new fields will be filled. In your example, the key field is
feature. Depending on the value of the columnfeature, you will send the value of the fielddescriptionto some of the new fields:Year, Genres, Director, orActors. - You have to decide which field or fields make up the groups of rows. In our example, that field is
film. All rows with the same value for the fieldfilmmake up a different group. - Decide the rules that have to be applied in order to fill the new target fields. All rules follow this pattern:
- If the value for the key field is equal to
A, then put the value of the fieldBinto the new fieldC. - A sample rule could be: If the value for the field
feature(our key field) is equal toDirected by, put the value of the fielddescriptioninto the new fieldDirector.
- If the value for the key field is equal to
Once you are clear about these three things, all you have to do is fill the Row denormaliser configuration window to tell PDI how to do this task.
- Fill the key field textbox with the name of the key field. In the example, the field is
feature. - Fill the upper grid with the fields that make up the grouping. In this case, it is
film. - Finally, fill the lower grid. This grid contains the rules for the new fields. Fill it following this example:
To add this rule ...
Fill a row like this ...
If the value for the key field is equal to
A, put the value of the fieldBinto the new fieldC.Key value:
AValue fieldname:
BTarget fieldname:
C
This is how you fill the row for the sample rule:
|
If the value for the field |
Key value:
Value fieldname:
Target fieldname:
|
For every rule you must fill a different row in the target fields' grid.
Let's see how the Row denormalizer works for the following sample rows:

PDI creates an output row for the film Manon Des Sources. Then it processes every row looking for values to fill the new fields.
Let's take the first row. The value for the key field feature is Directed by. PDI searches in the target fields' grid to see if there is an entry where the Key value is Directed by; it finds it.
Then it puts the value of the field description as the content for the target field Director. The output row is now like this:
Now take the second row. The value for the key field feature is 'Produced by.'
PDI searches in the target fields' grid to see if there is an entry where the Key value is Produced by. It cannot find it, and the information for this row is lost.
The following screenshot shows the rule applied to the third sample row. It also shows how the final output row looks like:
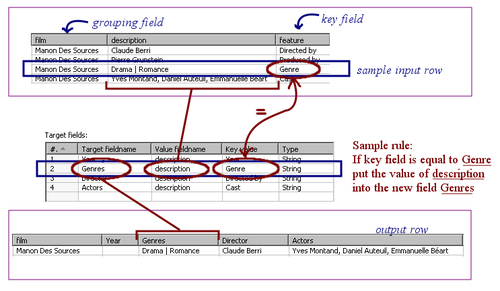
Note that the presence of rows is not mandatory for every key value entered in the target fields' grid. If an entry in the grid is not used, the target field is created anyway but it remains empty.
In this sample film, the year was not present. Then the field Year remained empty.
Take the output file for the Hero exercise to enhance the houses file from the previous chapter. You can also download the sample file from the Packt site. Create a transformation that reads that file and generates the following output: