
Suppose that by the time you are creating the transformation, the weights for calculating the weighted average are unknown. You can modify the transformation by using parameters. Let's do it:
- Open the transformation of the previous section and save it with a new name.
- Press Ctrl+T to open the Transformation properties dialog window.
- Select the Parameters tab and fill it like here:
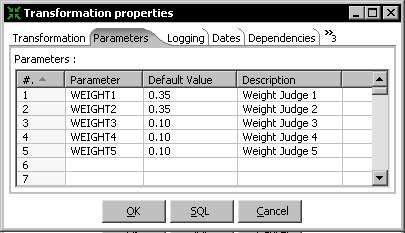
- Replace the JavaScript step by a new one and double-click it.
- Expand the Transform Scripts branch of the tree at the left of the window.
- Right-click the script named
Script 1, select Rename, and typemainas the new name. - Position the mouse cursor over the editing window and right-click to bring up the following contextual menu:
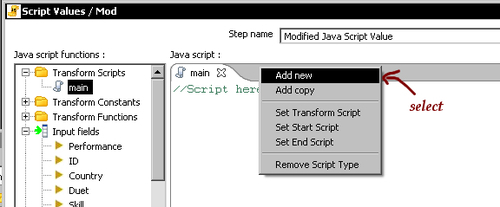
- Select Add new to add the script, which will execute before your main code.
- A new script window appears. The script is added to the list of scripts under Transform Scripts.
- Bring up the contextual menu again, but this time clicking on the title of the new script. Select Set Start Script.
- Right-click the script in the tree list, and rename the new script as
Start. - In the editing area of the new script, type the following code to bring the transformation parameters to the JavaScript code:
w1 = str2num(getVariable('WEIGHT1',0)); w2 = str2num(getVariable('WEIGHT2',0)); w3 = str2num(getVariable('WEIGHT3',0)); w4 = str2num(getVariable('WEIGHT4',0)); w5 = str2num(getVariable('WEIGHT5',0)); writeToLog('Getting weights...'), - Select the main script by clicking on its title and type the following code:
var wAverage; wAverage = w1 * Judge1 + w2 * Judge2 + w3 * Judge3 + w4 * Judge4 + w5 * Judge5; writeToLog('row:' + getProcessCount('r') + ' wAverage:' + num2str(wAverage)); if (wAverage >=7) trans_Status = CONTINUE_TRANSFORMATION; else trans_Status = SKIP_TRANSFORMATION; - Click Get variables to add the
wAveragevariable to the grid. - Close the JavaScript window.
- With the JavaScript step selected, click on the Preview this transformation button.
- When the preview window appears, click on Configure.
- In the window that shows up, modify the parameters as follows:
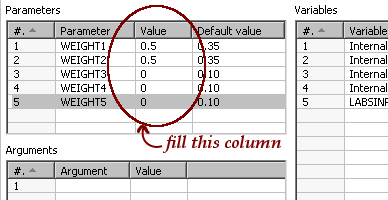
- Click Launch.
- The preview window shows this data:
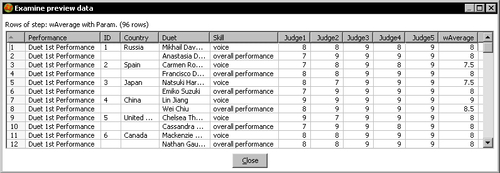
- The log window shows this:
... 2009/07/23 14:46:54 - wAverage with Param..0 - Getting weights... 2009/07/23 14:46:54 - wAverage with Param..0 - row:1 wAverage:8 2009/07/23 14:46:54 - wAverage with Param..0 - row:2 wAverage:8 2009/07/23 14:46:54 - wAverage with Param..0 - row:3 wAverage:7.5 2009/07/23 14:46:54 - wAverage with Param..0 - row:4 wAverage:8 2009/07/23 14:46:54 - wAverage with Param..0 - row:5 wAverage:7.5 ...
You modified the code of the JavaScript step to use parameters.
First, you created four parameters for the transformation, containing the weights for the calculation.
Then in the JavaScript step, you created a Start script to read the variables. That script executed once, before the main script. Note that you didn't declare the variables. You could have done it, but it's not mandatory unless you intend to add them as output fields.
In the main script, the script that is executed for every row, you typed the code to calculate the average by using those variables instead of fixed numbers.
After the calculation of the average, you kept only the rows for which the average was greater or equal to 7. You did it by setting the value of trans_Status to CONTINUE_TRANSFORMATION for the rows you wanted to keep, and to SKIP_TRANSFORMATION for the rows you wanted to discard.
In the preview window, you could see that the average was calculated as a weighted average of the scores you provided, and that only the rows with an average greater or equal to 7 were kept.
The parameters that you put in the transformation dialog window are called named parameters. They can be used through the transformation as regular variables, as if you had created them before—for example, in the kettle.properties file.
Note
From the point of view of the transformation, the main difference between variables defined in the kettle.properties file and named parameters is that the named parameters have a default value that can be changed at the time you run the transformation.
In this case, the default values for the variables defined as named parameters WEIGHT1 to WEIGHT5 were 0.35, 0.35, 0.10, 0.10, and 0.10—the same that you had used in previous exercises. But when you executed, you changed the default and used 0.50, 0.50, 0, 0, and 0 instead. This caused the formula for calculating the weighted average to work as an average of the first two scores. Take, for example, the numbers for the first row of the file. Consider the following code line:
wAverage = w1 * Judge1 + w2 * Judge2 + w3 * Judge3 + w4 * Judge4 + w5 * Judge5;
It was calculated as:
wAverage = 0.50 * 8 + 0.50 * 8 + 0 * 9 + 0 * 8 + 0 * 9;
giving a weighted average equal to 8.
Note that the named parameters are ready to use through the transformation as regular variables. You can see and use them at any place where the icon with the dollar sign is present.
If you want to use a named parameter or any other Kettle variable such as LABSINPUT or java.io.tmpdir inside the JavaScript code, you have to use the getVariable() function as you did in the Start script.
When you run the transformation from the command line, you also have the possibility to specify values for named parameters. For details about this, check Appendix B.
The JavaScript step allows you to create multiple scripts. The Transformation Script list displays a list with all scripts of the step.
In the tutorial, you added a special script named Start and used it to read the variables. The Start Script is a script that executes only once, before the execution of the main script you already know.
The Main script, the script that is created by default, executes for every row. As this script is executed after the start script, all variables defined in the main script there are accessible here. As an example of this, in the tutorial you used the start script to set values for the variables w1 through w5. Then in the main script you used those variables.
It is also possible to have an End Script that executes at the end of the execution of the step, that is, after the main script has been executed for all rows.
Note
When you create a Start or an End script, don't forget to give it a name so that you can recognize it. If you don't, you may get confused because nothing in the step shows you the type of the scripts.
Beyond main, start, and end scripts, you can use extra scripts to avoid overloading the main script with code. The code in the extra scripts will be available after the execution of the special function LoadScriptFromTab().
Note that in the exercises, you wrote some text to the log by using the writeToLog() function. That had the only purpose of showing you that the start script executed at the beginning and the main script executed for every row. You can see this sequence in the execution log.
In the tree to the left-hand side of the JavaScript window, under Transformation Constants, you have a list of predefined constants. You can use those constants to change the value of the predefined variable, trans_Status, such as:
trans_Status = SKIP_TRANSFORMATION
Here is how it works:
|
Value of the |
Effect on the current row |
|---|---|
|
|
The current row is removed from the dataset |
|
|
The current row is retained |
|
|
The current row causes abortion of the transformation |
In other words, you can use that constant to control what will happen to the rows. In the exercise you put:
if (wAverage >=7) trans_Status = CONTINUE_TRANSFORMATION; else trans_Status = SKIP_TRANSFORMATION;
This means a row where the average is greater than or equal to 7 will continue its way to the following steps. On the contrary, a row with a lower average will be discarded.
Look at the following screenshot:
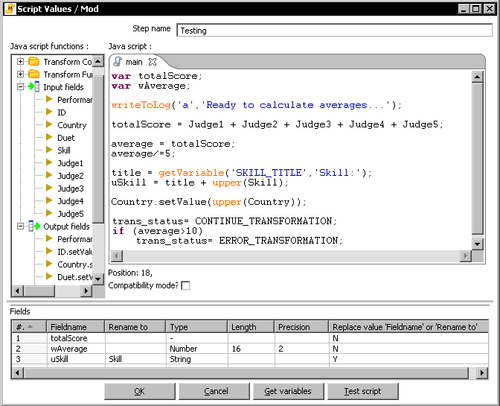
Does it look good? Well, it is not. There are seven errors in it. Can you find them?
Modify the last tutorial. By using a JavaScript step, keep the top 10 performances, that is, the 10 performances with the best average.
If you are a Java programmer, or just curious, you will like to know that you can access Java libraries from inside the JavaScript step. On the book site there is a jar file named pdi_chapter_5.jar. The jar file contains a class with two methods—w_average() and r_average(), for calculating a weighted average and a regular average.
Here is what you have to do:
- Download the file from Packt's site, copy it to the
libextfolder inside the PDI installation folder, and restart Spoon. - Replace the JavaScript calculation of the averages by a call to one of these methods. You'll have to specify the complete name of the class. Consider the next line for example:
wAverage = Packages.Averages.w_average(Judge1, Judge2, Judge3, Judge4, Judge5);
- Preview the transformation and verify that it works properly.
The Java file is available as well. You can change it by adding new methods and trying them from PDI.
Likewise, you can try using any Java objects, as long as they are in PDI's classpath. Don't forget to type the complete name as in the following examples:
java.lang.Character.isDigit(c); var my_date = new java.util.Date(); var val = Math.floor(Math.random()*100);