
An International Musical Contest will take place and 24 countries will participate, each presenting a duet. Your task is to hire interpreters so the contestants can communicate in their native language. In order to do that, you need to find out the language they speak:
- Create a new transformation.
- By using a Get Data From XML step, read the
countries.xmlfile that contains information about countries that you used in Chapter 2. - Drag a Filter rows step to the canvas.
- Create a hop from the Get data from XML step to the Filter rows step.
- Edit the Filter rows step and create the condition-
isofficial= T. - Click the Filter rows step and do a preview. The list of previewed rows will show the countries along with the official languages:
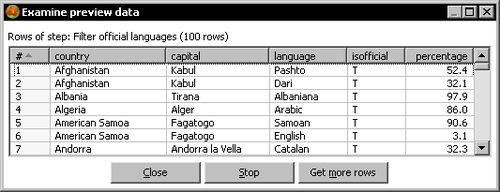
Now let's create the main flow of data:
- From the book website download the list of contestants. It looks like this:
ID;Country;Duet 1;Russia;Mikhail Davydova ;;Anastasia Davydova 2;Spain;Carmen Rodriguez ;;Francisco Delgado 3;Japan;Natsuki Harada ;;Emiko Suzuki 4;China;Lin Jiang ;;Wei Chiu 5;United States;Chelsea Thompson ;;Cassandra Sullivan 6;Canada;Mackenzie Martin ;;Nathan Gauthier 7;Italy;Giovanni Lombardi ;;Federica Lombardi
- In the same transformation, drag a Text file Input step to the canvas and read the downloaded file.
- Expand the Lookup category of steps.
- Drag a Stream lookup step to the canvas.
- Create a hop from the Text file input you just created, to the Stream lookup step.
- Create another hop from the Filter rows step to the Stream lookup step.
- Edit the Stream lookup step by double-clicking it.
- In the Lookup step drop-down list, select Filter official languages, the step that brings the list of languages.
- Fill the grids in the configuration window as follows:
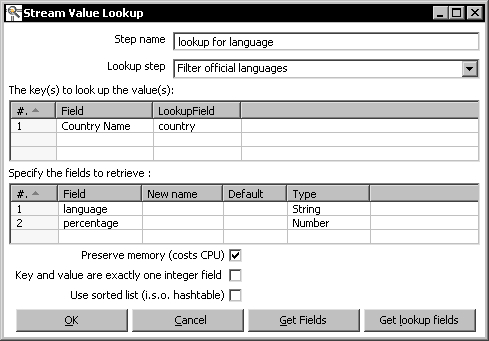
Note that
Country Nameis a field coming from the text file stream, while the country field comes from the countries stream. - Click OK.
- The hop that goes from the Filter rows step to the Stream lookup step changes its look and feel, to show that this is the stream where the Stream lookup is going to look:
- After the Stream lookup, add a Filter rows step.
- In the Filter rows step, type the condition
language-IS NOT NULL. - By using a Select values step, rename the fields
Duet, Country NameandlanguagetoName, Country, andLanguage. - Drag a Text file output step to the canvas and create the file
people_and_languages.txtwith the selected fields. - Save the transformation.
- Run the transformation and check the final file, which should look like this:
Name|Country|Language Mikhail Davydova|Russia| Anastasia Davydova|Russia| Carmen Rodriguez|Spain|Spanish Francisco Delgado|Spain|Spanish Natsuki Harada|Japan|Japanese Emiko Suzuki|Japan|Japanese Lin Jiang|China|Chinese Wei Chiu|China|Chinese Chelsea Thompson|United States|English Cassandra Sullivan|United States|English Mackenzie Martin|Canada|French Nathan Gauthier|Canada|French Giovanni Lombardi|Italy|Italian Federica Lombardi|Italy|Italian
First of all, you read a file with information about countries and the languages spoken in those countries.
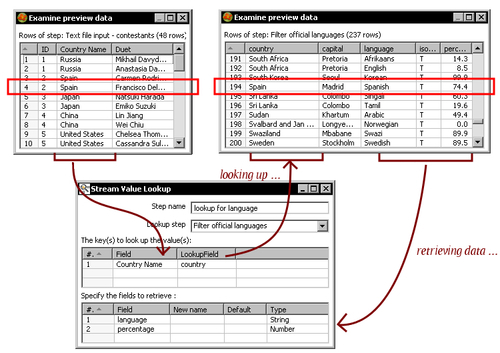
Then you read a list of people along with the country they come from. For every row in this list, you told Kettle to look for the country (Country Name field) in the countries stream (country field), and to give you back a language and the percentage of people that speaks that language (language and percentage fields). Let's explain it with a sample row: The row for Francisco Delgado from Spain. When this row gets to the Stream lookup step, Kettle looks in the list of countries for a row with the country Spain. It finds it. Then, it returns the value of the columns language and percentage: Spanish and 74.4.
Now take another sample row—the row with the country Russia. When the row gets to the Stream lookup step, Kettle looks for it in the list of countries, but it doesn't find it. So what you get as language is a null string.
Whether the country is found or not, two new fields are added to your stream—language and percentage.
After the Stream lookup step, you discarded the rows where language is null, that is, those whose country wasn't found in the list of countries.
With the successful rows you generated an output file.
The Stream lookup step allows you to look up data in a secondary stream.
You tell Kettle which of the incoming streams is the stream used to look up, by selecting the right choice in the Lookup step list.
The upper grid in the configuration window allows you to specify the names of the fields that are used to look up.
In the left column, Field, you indicate the field of your main stream. You can fill this column by using the Get Fields button, and deleting all the fields you don't want to use for the search.
In the right column, Lookup Field, you indicate the field of the secondary stream.
When a row of data comes to the step, a lookup is made to see if there is a row in the secondary stream for which, every pair (Field, LookupField) in the grid has the value of Field equal to the value of LookupField. If there is one, the look up will be successful.
In the lower grid, you specify the names of the secondary stream fields that you want back as a result of the look up. You can fill this column by using the Get lookup fields button, and deleting all the fields you don't want to retrieve.
After the lookup, new fields are added to your dataset—one for every row of this grid.
For the rows for which the look up is successful, the values for the new fields will be taken from the lookup stream.
For the others, the fields will remain null, unless you set a default value.
When you use a Stream lookup, all lookup data is loaded into memory. Then the stream lookup is made using a hash table algorithm. Even if you don't know how this algorithm works, it is important that you know the implications of using this step:
- First, if the data where you look is huge, you take the risk of running out of memory.
- Second, only one row is returned per key. If the key you are looking for is present more than once in the lookup stream, only one will be returned—for example, in the tutorial where there are more than one official languages spoken in a country, you get just one. Sometimes you don't care, but on some occasions this is not acceptable and you have to try some other methods. You'll learn other ways to do this later in the book.
The tutorial where you counted the words in a file worked pretty well, but you may have noticed that it has some details you can fix or enhance.
You discarded a very small list of words, but there are much more that are quite usual in English—prepositions, pronouns, auxiliary verbs, and many more. So here is the challenge: Get a list of commonly used words and save it in a file. Instead of excluding words from a small list as you did with a Filter rows step, exclude the words that are in your common words file.