
Let's use a Switch/Case step to replace the nested Filter Rows steps shown in the preceding diagram
- Create a transformation like the following:
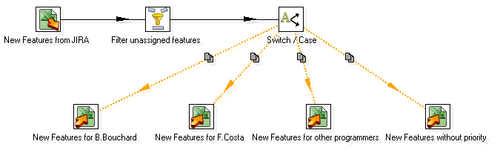
- You will find the Switch/Case step in the Flow category of steps.
- Note that the hops arriving to the Excel Output steps look strange. They are dotted orange lines. This look and feel shows you that the target steps are unreachable. In this case, it means that you still have to configure the Switch/Case step. Double-click it and fill it like here:
- Save the transformation and run it
- Open the Excel files generated to see that the transformation distributed the task among the files based on the given conditions.
In this tutorial you learned to use the Switch/Case step. This step routes rows of data to one or more target steps based on the value encountered in a given field.
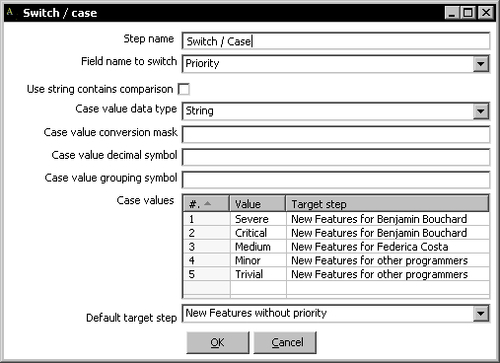
In the Switch/Case step configuration window, you told Kettle where to send the row depending on a condition. The condition to evaluate was the equality of the field set in Field name to switch and the value indicated in the grid. In this case, the field name to switch is Priority, and the values against which it will be compared are the different values for priorities: Severe, Critical, and so on. Depending on the values of the Priority field, the rows will be sent to any of the target steps. For example, the rows where Priority=Medium, will be sent toward the target step New Features for Federica Costa.
Note that it is possible to specify the same target step more than once.
The Default target step represents the step where the rows that don't match any of the case values are sent. In this example, the rows with a priority not present in the list will be sent to the step New Features without priority.
Open the transformation you created in the Finding out which language people speak tutorial in Chapter 3. If you run the transformation and check the content of the output file, you'll notice that there are missing languages. Modify the transformation so that it generates two files—one with the rows where there is a language, that is, the rows for which the lookup didn't fail, and another file with the list of countries not found in the countries.xml file.
Continuing with the contestant exercise, suppose that the number of interpreters you will hire depends on the number of people that speak each language:
|
Number of people that speaks the language |
Number of interpreters |
|---|---|
|
Less than 3 |
1 |
|
Between 3 and 6 |
2 |
|
More that 6 |
3 |
You want to create a file with the languages with a single interpreter, another file with the languages with two interpreters, and a final file with the languages with three interpreters. Which of the following would solve your situation when it comes to splitting the languages into three output streams:
a. A Number range step followed by a Switch/Case step.
b. A Switch/Case step.
c. Both