
In this tutorial you will use the output of the denormalizing process from the previous chapter. You will calculate the age of the films and classify them according to their age.
- Get the file with the films. You can take the transformation that denormalized the data and generate the file with a Text file output step, or you can take a sample file from the Packt website.
- Create a new transformation and read the file with a Text file input step.
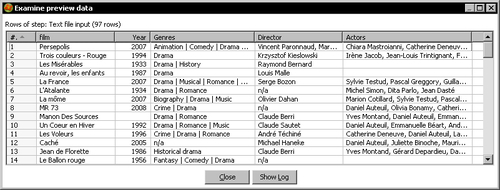
- Do a preview of the data. You will see the following:
- After the Text file input step, add a Get System Info step.
- Edit the step, add a new field named
today, and chooseToday 00:00:00as its value. - Add a JavaScript step.
- Edit the step and type the following piece of code:
var diff; film_date = str2date('01/01/' + Year, 'dd/MM/yyyy'), diff = dateDiff(film_date,today,"y"); - Click on Get variables to add
diffas a new field. - Add a Number range step, edit it, and fill its window as follows:

- With a Sort rows step, sort the data by
diff. - Finally, add a Group by step and double-click to edit it.
- As group field put
age_of_film. In the Aggregates grid create a field namednumber_of_filmsto hold the number of films with that age. Putfilmas the Subject and selectNumber of values (N)as the Type. - Add a Dummy step at the end and do a preview. You will be surprised by an error like this:
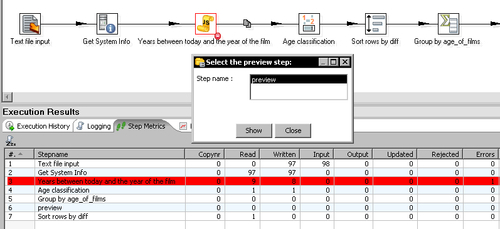
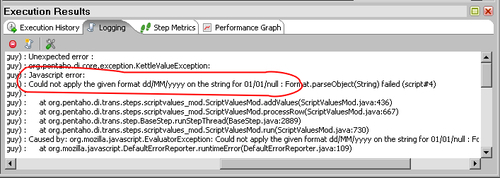
- Look at the logging window. It looks like this:
- Now drag Write to log step to the canvas from the Utility category.
- Create a hop from the JavaScript step to this new step.
- Select the JavaScript step, right-click it to bring up a contextual menu, and select Define error handling....
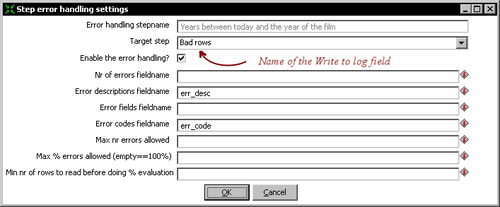
- The error handling settings window appears. Fill it like shown:
- Click on OK.
- Save the transformation and do a new preview on the Dummy step. You will see this:
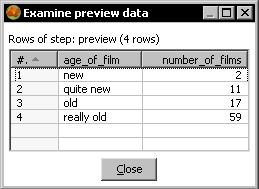
- The logging window will show you this:
... - Bad rows.0 - ... - Bad rows.0 - ------------> Linenr 1------------------------- ... - Bad rows.0 - null ... - Bad rows.0 - ... - Bad rows.0 - Javascript error: ... - Bad rows.0 - Could not apply the given format dd/MM/yyyy on the string for 01/01/null : Format.parseObject(String) failed (script#4) ... - Bad rows.0 - ... - Bad rows.0 - --> 4:0 ... - Bad rows.0 - SCR-001 ... - Bad rows.0 - ... - Bad rows.0 - ==================== ... - Bad rows.0 - ... - Bad rows.0 - ------------> Linenr 2------------------------- ... - Bad rows.0 - null ... - Bad rows.0 - ... - Bad rows.0 - Javascript error: ... - Bad rows.0 - Could not apply the given format dd/MM/yyyy on the string for 01/01/null : Format.parseObject(String) failed (script#4) ... - Bad rows.0 - ... - Bad rows.0 - --> 4:0 ...
The date was cut from the log for clarity of the log messages.
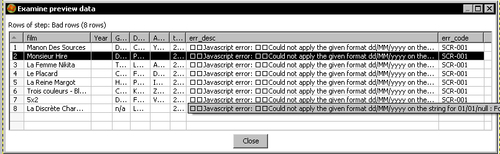
- Now do a preview on the Write to log step. This is what you see:
You created a transformation to read a list of films and group them according to their age, that is, how old the movie is. You were surprised by an unexpected error caused by the rows in which the year was undefined. Then you implemented error handling to capture that error and to avoid the abortion of the transformation. With the treatment of the error, you split the stream in two:
- The rows that caused the error went to a new stream that wrote to the log information about the error
- The rows that passed the JavaScript step without problem went through the main path
With the error handling functionality, you can capture errors that otherwise would cause the transformation to halt. Instead of aborting, the rows that cause the errors are sent to a different stream for further treatment.
You don't need to implement error handling in every step, but in those where it's more likely to have errors when running the transformation. A typical situation where you should consider handling errors is in a JavaScript step. A code that works perfectly when designing might fail while executing against real data, where the most common errors are related to data type conversions or indexes out of range. Another common use of error handling is when working with databases (you will see more on this later in the book).
To configure the error handling, you have to right-click the step and select Define Error handling.
Note
Note that not all steps support error handling. The Define Error handling option is available only when clicking on steps that support it.
After opening the settings window, you have to fill it just as you did in the tutorial. You have to specify the target step for the bad rows along with the name of the extra fields being added, as part of the treatment of errors:
|
Field |
Description |
|---|---|
|
Nr of errors fieldname |
Name for the field that will have the number of errors |
|
Error fields fieldname |
Name for the field that will have the name of the field(s) that caused the errors |
|
Error codes fieldname |
Name for the field that will have the error code |
|
Error descriptions fieldname |
Name for the field that will have the error description |
The first two are trivial. The last two deserve an explanation. The values for the error code and description fields are the same as those you see in the Logging tab when you don't trap the error. In the tutorial there was a JavaScript error with code SCR-001 and description JavaScript error: Could not apply the given format.... You saw this code as well as its description in the Logging tab when you didn't trap the error and the transformation crashed, and in the preview you made at the end of the error stream. This particular error was a JavaScript one, but the kind of error you get depends always on the kind of step where it occurs.
You are not forced to fill all the textboxes in the error setting window. Only the fields for which you provide a name will be added to the dataset. By doing a preview on the target step, you can see the extra fields that were added.