
Understanding TCP/IP
As we mentioned in the introduction, computers use a protocol as a common language for communication. A protocol is a set of rules that govern communications, much like a language in human terms. Of the myriad protocols out there, the key one to understand is the TCP/IP suite, which is actually a collection of different protocols that work together to deliver connectivity. Consequently, it’s the only one listed on the A+ exam objectives. In the following sections, we’ll start with a look at its overall structure and then move into key protocols within the suite.
TCP/IP Structure
The Transmission Control Protocol/Internet Protocol (TCP/IP) suite is the most popular network protocol in use today, thanks mostly to the rise of the Internet. While the protocol suite is named after two of its hardest-working protocols, Transmission Control Protocol (TCP) and Internet Protocol (IP), TCP/IP actually contains dozens of protocols working together to help computers communicate with one another.
TCP/IP is robust and flexible. For example, if you want to ensure that the packets are delivered from one computer to another, TCP/IP can do that. If speed is more important than guaranteed delivery, then TCP/IP can ensure that too. The protocol can work on disparate operating systems such as UNIX, Linux, and Windows. It can also support a variety of programs, applications, and required network functions. Much of its flexibility comes from its modular nature.
You’re familiar with the seven-layer OSI model we discussed in Chapter 6, “Networking Fundamentals.” Every protocol that’s created needs to accomplish the tasks (or at least the key tasks) outlined in that model. The structure of TCP/IP is based on a similar model created by the United States Department of Defense: the Department of Defense (DOD) model. The DOD model has four layers that map to the seven OSI layers, as shown in Figure 7-1.
Figure 7-1: The DOD and OSI models
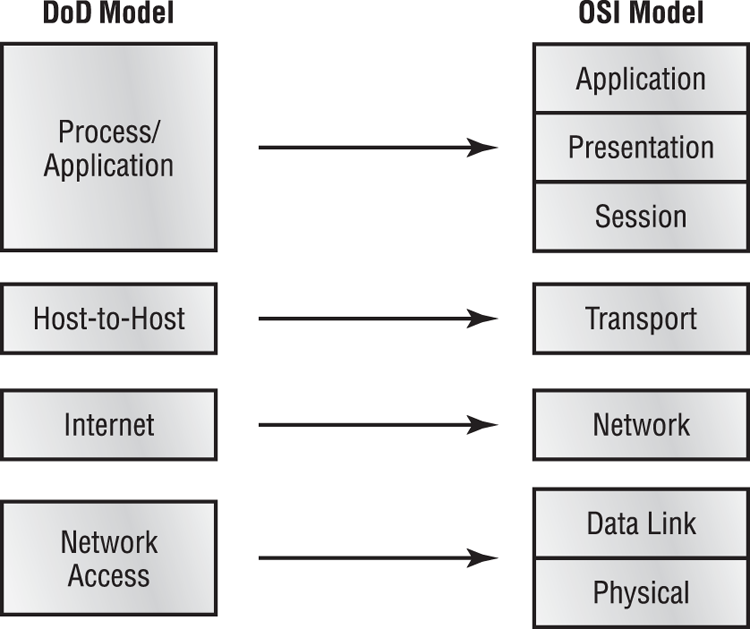
The overall functionality between these two models is virtually identical; the layers just have different names. For example, the Process/Application layer of the DOD model is designed to combine the functionality of the top three layers of the OSI model. Therefore, any protocol designed against the Process/Application layer would need to be able to perform all functions associated with the Application, Presentation, and Session layers in the OSI model.
TCP/IP’s modular nature and common protocols are shown in Figure 7-2.
Figure 7-2: TCP/IP protocol suite
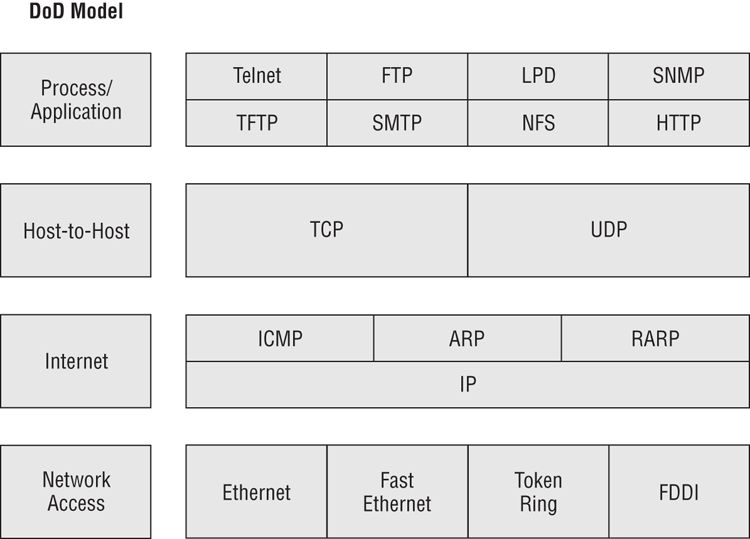
The majority of TCP/IP protocols are located at the Process/Application layer. These include some protocols you are probably already familiar with, such as Hypertext Transfer Protocol (HTTP), File Transfer Protocol (FTP), Simple Mail Transfer Protocol (SMTP), Post Office Protocol (POP), and others.
At the Host-to-Host layer, there are only two protocols: TCP and User Datagram Protocol (UDP). Most applications will use one or the other to transmit data, although some can use both but will do so for different tasks.
The most important protocol at the Internet layer is IP. This is the backbone of TCP/IP. Other protocols at this layer work in conjunction with IP, such as Internet Control Message Protocol (ICMP) and Address Resolution Protocol (ARP).
You’ll notice that the Network Access layer doesn’t have any protocols per se. This layer describes the type of network access method you are using, such as Ethernet, Token Ring, or others.
Process/Application Layer Protocols
As we mentioned in the previous section, most of the protocols within the TCP/IP suite are at the Process/Application layer. This is the layer of differentiation and flexibility. For example, if you want to browse the Internet, the HTTP protocol is designed for that. FTP is optimized for file downloads, and RDP allows you to connect to a remote computer and manage programs.
Before we get into the protocols themselves, let’s take a quick look into a few key points on the TCP/IP suite’s flexibility. There are literally dozens of protocols at the Process/Application layer, and they have been created over time as networking needs arose. Take HTTP, for example. The first official version was developed in 1991, nearly 20 years after TCP/IP was first implemented. Before this protocol was created, there weren’t any effective client-server request-response protocols at this layer. HTTP let the client (web browser) ask the web server for a page, and the web server would return it. Going one step further, there was a need for secure transactions over HTTP, hence the creation of HTTPS in 1994. As new applications are developed or new networking needs are discovered, developers can build an application or protocol that fits into this layer to provide the needed functionality. They just need to make sure the protocol delivers what it needs to and can communicate with the layers below it. The following sections will describe some of the more common Process/Application protocols—and the ones listed in the A+ exam objectives.
DHCP
Dynamic Host Configuration Protocol (DHCP) dynamically assigns IP addresses and other IP configuration information to network clients. Configuring your network clients to receive their IP addresses from a DHCP server reduces network administration headaches. We’ll cover the mechanics of how DHCP works later in this chapter when we talk about IP addressing.
DNS
You probably use Domain Name System (DNS) every day whether you realize it or not. Its purpose is to resolve hostnames to IP addresses. For example, let’s say you open your web browser and type in a Uniform Resource Locator (URL) such as http://www.sybex.com. Your computer needs to know the IP address of the server that hosts that website in order for you to connect to it. Through a DNS server, your computer resolves the URL to an IP address so communication can happen.
FTP
The File Transfer Protocol (FTP) is optimized to do what it says it does—transfer files. This includes both uploading and downloading files from one host to another. FTP is both a protocol and an application. Specifically, FTP lets you copy files, list and manipulate directories, and view file contents. You can’t use it to remotely execute applications.
Whenever a user attempts to access an FTP site they will be asked for a login. If it’s a public site, you can often just use the login name anonymous and then provide your email address as the password. Of course, there’s no rule saying you have to give your real email address if you don’t want to. If the FTP site is secured, you will need a legitimate login name and password to access it. If you are using a browser such as Internet Explorer to connect via FTP, the correct syntax in the address window is ftp://username:password@ftp.ftpsite.com.

HTTP
The most commonly used Process/Application layer protocol is HTTP. It manages the communication between a web server and client and lets you connect to and view all of the content you enjoy on the Internet.
HTTPS
The protocol used for most Internet traffic, HTTP, is not secure. To securely encrypt traffic between a web server and client, Hypertext Transfer Protocol Secure (HTTPS) can be used. HTTPS connections are secured using either Secure Sockets Layer (SSL) or Transport Layer Security (TLS).
From the client side, the most common issue you will encounter when HTTPS is in use on a website is that users may not know what the proper context is. To access most websites, you use http:// in the address bar. To get to a site using HTTPS, you need to use https:// instead.
IMAP
Internet Message Access Protocol (IMAP) is a secure protocol designed to download email. Its current version is version 4, or IMAP4. It’s becoming more and more common as the client-side email management protocol of choice, replacing the unsecure POP3. Most current email clients, such as Microsoft Outlook and Gmail, are configured to be able to use either IMAP4 or POP3.
IMAP4 has some definite advantages over POP3. First, IMAP4 works in connected and disconnected modes. With POP3, the client makes a connection to the email server, downloads the email, and then terminates the connection. IMAP4 allows the client to remain connected to the email server after the download, meaning that as soon as another email enters the inbox, IMAP4 notifies the email client and is ready to download it. Second, it also lets you store the email on the server, as opposed to POP3, which requires you to download it. Third, IMAP4 allows multiple clients to be simultaneously connected to the same inbox. This can be useful for BlackBerry users who have both Outlook and their BlackBerry operational at the same time or for cases where multiple users monitor the same mailbox, such as on a customer service account. IMAP4 allows each connected user or client to see changes made to messages on the server in real time.
LDAP
The Lightweight Directory Access Protocol (LDAP) is a directory services protocol based on the X.500 standard. LDAP is designed to access information stored in an information directory typically known as an LDAP directory or LDAP database.
On your network you probably have a lot of information such as employee phone books and email addresses, client contact lists, and infrastructure and configuration data for the network and network applications. This information might not get updated frequently, but you might need to access it from anywhere on the network, or you might have a network application that needs access to this data. LDAP provides you with the access, regardless of the client platform you’re working from. You can also use access control lists (ACLs) to set up who can read and change entries in the database using LDAP. A common analogy is that LDAP provides access to and the structure behind your network’s phone book.
POP3
For a long time now, Post Office Protocol 3 (POP3) has been the preferred protocol for downloading email. It’s being replaced by IMAP4 because IMAP4 includes security and more features than POP3.
RDP
Developed by Microsoft, the Remote Desktop Protocol (RDP) allows users to connect to remote computers and run programs on them. When you use RDP, you see the desktop of the computer you’ve logged in to on your screen. It’s like you’re really there, even though you’re not.
When you use RDP, the computer that you are sitting at is the client, and the computer you’re logging in to is the server. The server uses its own video driver to create video output and sends the output to the client using RDP. Conversely, all keyboard and mouse input from the client is encrypted and sent to the server for processing. RDP also supports sound, drive, port, and network printer redirection. In a nutshell, this means that if you could see, hear, or do it if you were sitting at the remote computer, you could see, hear, or do it at the RDP client too.
Services using this protocol can be great for telecommuters. It’s also very handy for technical support folks, who can log in and assume control over a remote computer. It’s a lot easier to troubleshoot and fix problems when you can see what’s going on and “drive”!
SFTP
The Secure File Transfer Protocol (SFTP) is used when you need to transfer files over a secure, encrypted connection.
SMB
Server Message Block (SMB) is another Microsoft-developed protocol. It’s used to provide shared access to files, printers, and other network resources. In a way, it functions a bit like FTP only with a few more options.
SMTP
We’ve already looked at a few protocols that are for downloading or receiving email. Simple Mail Transfer Protocol (SMTP) is the protocol most commonly used to send email messages. Because it’s designed to send only, it’s referred to as a push protocol. An email client locates its email server by querying the DNS server for a mail exchange (MX) record. After the server is located, SMTP is used to push the message to the email server, which will then process the message for delivery.
SNMP
Simple Network Management Protocol (SNMP) gathers and manages network performance information.
On your network, you might have several connectivity devices such as routers and switches. A management device called an SNMP server can be set up to collect data from these devices (called agents) and ensure that your network is operating properly. Although it’s mostly used to monitor connectivity devices, many other network devices are SNMP compatible as well. The most current version is SNMPv3.
SSH
Secure Shell (SSH) can be used to set up a secure Telnet session for remote logins or for remotely executing programs and transferring files. Because it’s secure, it was originally designed to be a replacement for the unsecure telnet command. A common client interface using SSH is called OpenSSH (www.openssh.com).

Telnet
It seems as though Telnet has been around since the beginning of time as a terminal emulation protocol. Someone using Telnet can log into another machine and “see” the remote computer in a window on their screen. Although this vision is text only, the user can manage files on that remote machine just as if they were logged in locally.
The problem with telnet and other unsecure remote management interfaces (such as rcp and ftp) is that the data they transmit, including passwords, is sent in plain text. Anyone eavesdropping on the line can intercept the packets and thus obtain usernames and passwords. SSH overcomes this by encrypting the traffic, including usernames and passwords.
Host-to-Host Layer Protocols
After the myriad protocols at the Process/Application layer, the simplicity of the Host-to-Host layer is welcome. At this layer there are two alternatives within the TCP/IP suite: TCP and UDP. The major difference between the two is that TCP guarantees packet delivery through the use of a virtual circuit and data acknowledgements and UDP does not. Because of this, TCP is often referred to as connection oriented, whereas UDP is connectionless. Because UDP is connectionless, it does tend to be somewhat faster, but we’re talking about milliseconds here.
Another key concept to understand about TCP and UDP is the use of port numbers. Imagine a web server that is managing connections from incoming users who are viewing web content and others who are downloading files. TCP and UDP use port numbers to keep track of these conversations and make sure the data gets to the right application and right end user. Conversely, when a client makes a request of a server, it needs to do so on a specific port to make sure the right application on the server hears the request. For example, web servers are listening for HTTP requests on port 80, so web browsers need to make their requests on that port.
A good analogy for understanding port numbers is to think of cable or satellite television. In this analogy, the IP address is your house. The cable company needs to know where to send the data. But once the data is in your house, which channel are you going to receive it on? If you want sports, that might be on one channel, but weather is on a different channel, and the cooking show is on yet another. Those channels are analogous to ports. You know that if you want a cooking show, you need to turn to channel 923 (or whatever). Similarly, the client computer on a network knows that if it needs to ask a question in HTTP, it needs to do it on port 80.
There are 65,536 ports numbered from 0 to 65535. Ports 0 through 1023 are called the well-known ports and are assigned to commonly used services, and 1024 through 49151 are called the registered ports. Anything from 49152 to 65535 is free to be used by application vendors. Fortunately, you don’t need to memorize them all.
Table 7-1 shows the ports used by some of the more common protocols. You should know each of these for the A+ exam.
Table 7-1: Common port numbers
| Service | Protocol | Port |
| FTP | TCP | 20, 21 |
| SSH | TCP | 22 |
| Telnet | TCP | 23 |
| SMTP | TCP | 25 |
| DNS | TCP/UDP | 53 |
| HTTP | TCP | 80 |
| DHCP | UDP | 67, 68 |
| POP3 | TCP | 110 |
| IMAP4 | TCP | 143 |
| SNMP | UDP | 161 |
| LDAP | TCP | 389 |
| HTTPS | TCP | 443 |
| SMB | TCP | 445 |
| RDP | TCP | 3389 |
A complete list of registered port numbers can be found at www.iana.org.

Internet Layer Protocols
At the Internet layer, there’s one key protocol and a few helpful support protocols. The main workhorse of TCP/IP is the Internet Protocol (IP), and it can be found here. IP is responsible for managing logical network addresses and ultimately getting data from point A to point B, even if there are dozens of points in between. We’ll cover IP addressing more in the next section.
There are three support protocols you should be aware of at this layer as well. Internet Control Message Protocol (ICMP) is responsible for delivering error messages. If you’re familiar with the ping utility, you’ll know that it utilizes ICMP to send and receive packets. Address Resolution Protocol (ARP) resolves logical IP addresses to physical MAC addresses built in to network cards. Reverse ARP (RARP) resolves MAC addresses to IP addresses.
Understanding IP Addressing
To communicate on a TCP/IP network, each device needs to have a unique IP address. Any device with an IP address is referred to as a host. This can include servers, workstations, printers, and routers. If you can assign it an IP address, it’s a host. As an administrator, you can assign the host’s IP configuration information manually, or you can have it automatically assigned by a DHCP server.
An IPv4 address is a 32-bit hierarchical address that identifies a host on the network. It’s typically written in dotted-decimal notation, such as 192.168.10.55. Each of the numbers in this example represents 8 bits (or 1 byte) of the address, also known as an octet. The same address written in binary (how the computer thinks about it) would be 11000000 10101000 00001010 00110111. As you can see, the dotted-decimal version is a much more convenient way to write these numbers!
The addresses are said to be hierarchical, as opposed to “flat,” because the numbers at the beginning of the address identify groups of computers that belong to the same network. Because of the hierarchical address structure, we’re able to do really cool things like route packets between local networks and on the Internet.
A great example of hierarchical addressing is your street address. Let’s say that you live in apartment 4B on 123 Main Street, Anytown, Kansas, USA. If someone sent you a letter via snail mail, the hierarchy of your address helps the postal service and carrier deliver it to the right place. First and broadest is USA. Kansas helps narrow it down a bit, and Anytown narrows it down more. Eventually we get to your street, the right number on your street, and then the right apartment. If the address space were flat (e.g., Kansas didn’t mean anything more specific than Main Street), or you could name your state anything you wanted to, it would be really hard to get the letter to the right spot.
Take this analogy back to IP addresses. They’re set up to logically organize networks to make delivery between them possible and then to identify an individual node within a network. If this structure weren’t in place, a huge, multinetwork space like the Internet probably wouldn’t be possible. It would simply be too unwieldy to manage.
A Quick Binary Tutorial
As we mentioned earlier, each IP address is written in four octets in dotted-decimal notation, but each octet represents 8 bits. A binary bit is a value with two possible states: on equals 1, and off equals 0. If the bit is turned on, it has a decimal value based upon its position within the octet. An off bit always equals zero. Take a look at Figure 7-3, which will help illustrate what we mean.
Figure 7-3: Binary values
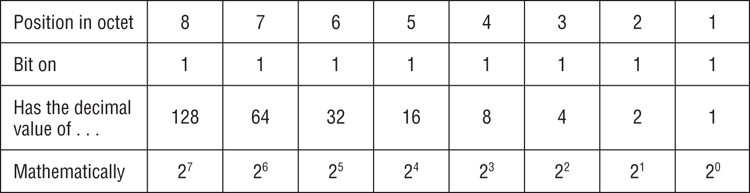
If all of the bits in an octet are off, or 00000000, the corresponding decimal value is 0. If all bits in an octet are on, you would have 11111111, which is 255 in decimal.
Where it starts to get more entertaining is when you have combinations of zeroes and ones. For example, 10000001 is equal to 129 (128 + 1), and 00101010 is equal to 42 (32 + 8 + 2).
As you work with IPv4 addresses, you’ll see certain patterns emerge. For example, you may begin to find yourself able to count quickly from left to right in an octet pattern, such as 128, 192, 224, 240, 248, 252, 254, and 255. That’s what you get if you have (starting from the left) 1, 2, 3, and so forth up to 8 bits on in sequence in the octet.
It’s beyond the scope of this book to get into too much detail on binary-to-decimal conversion, but this primer should get you started.
Parts of the IP Address
Each IP address is made up of two components: the network ID and the host ID. The network portion of the address always comes before the host portion. Because of the way IP addresses are structured, the network portion does not have to be a specific fixed length. In other words, some computers will use 8 of the 32 bits for the network portion and the other 24 for the host portion, while other computers might use 24 bits for the network portion and the remaining 8 bits for the host portion. Here are a few rules you should know about when working with IP addresses:
- All host addresses on a network must be unique.
- On a routed network (such as the Internet), all network addresses must be unique as well.
- Neither the network ID nor the host ID can be set to all 0s. A host ID portion of all 0s means “this network.”
- Neither the network ID nor the host ID can be set to all 1s. A host ID portion of all 1s means “all hosts on this network,” commonly known as a broadcast address.
Computers are able to differentiate where the network ID ends and the host address begins through the use of a subnet mask. This is a value written just like an IP address and may look something like 255.255.255.0. Any bit that is set to a 1 in the subnet mask makes the corresponding bit in the IP address part of the network ID (regardless of whether the bit in the IP address is on or off). The rest will be the host ID. The number 255 is the highest number you will ever see in IP addressing, and it means that all bits in the octet are set to 1.
Here’s an example based on two numbers we have used in this chapter. Look at the IP address of 192.168.10.55. Let’s assume that the subnet mask in use with this address is 255.255.255.0. This indicates that the first three octets are the network portion of the address and the last octet is the host portion, therefore the network portion of this ID is 192.168.10 and the host portion is 55.
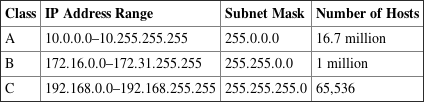
IPv4 Address Classes
The designers of TCP/IP designated classes of networks based on the first three bits of the IP address. As you will see, classes differ in how many networks of each class can exist and the number of unique hosts each network can accommodate. Here are some characteristics of the three classes of addresses you will commonly deal with:
Table 7-2 shows the IPv4 classes, their ranges, and their default subnet masks.
Table 7-2: IPv4 address classes
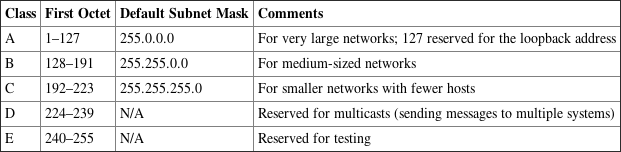
DHCP and DNS
Two critical TCP/IP services you need to be aware of are Dynamic Host Configuration Protocol (DHCP) and Domain Name System (DNS). Both are services that need to be installed on a server and both provide key functionality to network clients.
A DHCP server can be configured to automatically provide IP configuration information to clients. The following configuration information is typically provided:
- IP address
- Subnet mask
- Default gateway (the “door” to the outside world)
- DNS server address
DHCP servers can provide a lot more than the items on this list, but those are the most common. When a DHCP-configured client boots up, it sends out a broadcast on the network (called a DHCP DISCOVER) requesting a DHCP server. The DHCP server initially responds to the request and then fulfills the request by returning configuration information to the client.
The alternative to DHCP, of course, is for an administrator to enter in the IP configuration information manually for each host. This is called static IP addressing and is very administratively intensive as compared to DHCP’s dynamic addressing.
DNS has one function on the network, and that is to resolve host names to IP addresses. This sounds simple enough, but it has profound implications.
Think about using the Internet. You open your browser, and in the address bar, you type the name of your favorite website, something like www.google.com, and press Enter. The first question your computer asks is, “Who is that?” Your machine requires an IP address to connect to the website. The DNS server provides the answer, “That is 72.14.205.104.” Now that your computer knows the address of the website you want, it’s able to traverse the Internet to find it.
Think about the implications of that for just a minute. We all probably use Google several times a day, but in all honesty how many of us know its IP address? It’s certainly not something we are likely to have memorized. Much less, how could you possibly memorize the IP addresses of all of the websites you visit? Because of DNS, it’s easy to find resources. Whether you want to find Coca-Cola, Toyota, Amazon.com, or thousands of other companies, it’s usually pretty easy to figure out how. Type in the name with a .com on the end of it and you’re usually right. The only reason this is successful is that DNS is there to perform resolution of that name to the corresponding IP address.
DNS works the same way on an intranet (a local network not attached to the Internet) as it does on the Internet. The only difference is that instead of helping you find www.google.com, it may help you find Jenny’s print server or Joe’s file server. From a client-side perspective, all you need to do is configure the host with the address of a legitimate DNS server and you should be good to go.
Public vs. Private IP Addresses
All of the addresses that are used on the Internet are called public addresses. They must be purchased, and only one computer can use any given public address at one time. The problem that presented itself was that the world was soon to run out of public IP addresses while the use of TCP/IP was growing. Additionally, the structure of IP addressing made it impossible to “create” or add any new addresses to the system.
To address this, a solution was devised to allow for the use of TCP/IP without requiring the assignment of a public address. The solution was to use private addresses. Private addresses are not routable on the Internet. They were intended to be used on private networks only. Because they weren’t intended to be used on the Internet, it freed us from the requirement that all addresses be globally unique. This essentially created an infinite number of IP addresses that companies could use within their own network walls.
While this solution helped alleviate the problem of running out of addresses, it created a new one. The private addresses that all of these computers have aren’t globally unique, but they need to be in order to access the Internet.
A service called Network Address Translation (NAT) was created to solve this problem. NAT runs on your router and handles the translation of private, nonroutable IP addresses into public IP addresses. There are three ranges reserved for private, nonroutable IP addresses, as shown in Table 7-3.
Table 7-3: Private IP address ranges
These private addresses cannot be used on the Internet and cannot be routed externally. The fact that they are not routable on the Internet is actually an advantage because a network administrator can use them to essentially hide an entire network from the Internet.
This is how it works: The network administrator sets up a NAT-enabled router, which functions as the default gateway to the Internet. The external interface of the router has a public IP address assigned to it that has been provided by the ISP, such as 155.120.100.1. The internal interface of the router will have an administrator-assigned private IP address within one of these ranges, such as 192.168.1.1. All computers on the internal network will then also need to be on the 192.168.1.0 network. To the outside world, any request coming from the internal network will appear to come from 155.120.100.1. The NAT router translates all incoming packets and sends them to the appropriate client. This type of setup is very common today.
You may look at your own computer, which has an address in a private range, and wonder, “If it’s not routable on the Internet, then how am I on the Internet?” Remember, the NAT router technically makes the Internet request on your computer’s behalf, and the NAT router is using a public IP address.
Automatic Private IP Addressing
Automatic Private IP Addressing (APIPA) is a TCP/IP standard used to automatically configure IP-based hosts that are unable to reach a DHCP server. APIPA addresses are in the 169.254.0.0 range with a subnet mask of 255.255.0.0. If you see a computer that has an IP address beginning with 169.254, you know that it has configured itself.
Typically the only time you will see this is when a computer is supposed to receive configuration information from a DHCP server but for some reason that server is unavailable. Even while configured with this address, the client will continue to broadcast for a DHCP server so it can be given a real address once the server becomes available.
APIPA is also sometimes known as zero configuration networking or address autoconfiguration. If you are setting up a small local area network that had no need to communicate with any networks outside of itself, you can use APIPA to your advantage. Set the client computers to automatically receive DHCP addresses, but don’t set up a DHCP server. The clients will configure themselves and be able to communicate with each other using TCP/IP. The only downside is that this will create a little more broadcast traffic on your network. This solution is only really effective for a nonrouted network of fewer than 100 computers.
IPv6
The present incarnation of TCP/IP that is used on the Internet was originally developed in 1973. Considering how fast technology evolves, it’s pretty amazing to think that the protocol still enjoys immense popularity nearly 40 years later. This version is known as IPv4.
There are a few problems with IPv4 though. One is that we’re quickly running out of available network addresses, and the other is that TCP/IP can be somewhat tricky to configure.
If you’ve dealt with configuring custom subnet masks, you may nod your head at the configuration part, but you might be wondering how we can run out of addresses. After all, IPv4 has 32 bits of addressing space, which allows for nearly 4.3 billion addresses! With the way it’s structured, only about 250 million of those addresses are actually usable, and all of those are pretty much spoken for.
A new version of TCP/IP has been developed and it’s called IPv6. Instead of a 32-bit address, it provides for 128-bit addresses. That will provide for 3.4 x 1038 addresses, which theoretically should be more than enough that globally they will never run out. (Famous last words, right?)
IPv6 also has many standard features that are optional (but useful) in IPv4. While the addresses may be more difficult to remember, the automatic configuration and enhanced flexibility make the new version sparkle compared to the old one. Best of all, it’s backward compatible with and can run on the computer at the same time as IPv4, so networks can migrate to IPv6 without a complete restructure.
Understanding IPv6 Addressing
Understanding the IPv6 addressing scheme is probably the most challenging part of the protocol enhancement. The first thing you’ll notice is that, of course, the address space is longer. The second is that IPv6 uses hexadecimal notation instead of the familiar dotted decimal of IPv4. Its 128-bit address structure looks something like this.

The new address is composed of eight 16-bit fields, each represented by four hexadecimal digits and separated by colons. The letters in an IPv6 address are not case sensitive. IPv6 has three address classes: unicast, anycast, and multicast. A unicast address identifies a single node on the network. An anycast address refers to one that has been assigned to multiple nodes. A packet addressed to an anycast address will be delivered to the closest node. Sometimes you will hear this referred to as one-to-nearest addressing. Finally, a multicast address is one used by multiple hosts. Think of it as a controlled, small-scale broadcast. Speaking of broadcasts, IPv6 does not employ broadcast addresses. That functionality is handled by multicasts. Each network interface can be assigned one or more addresses.
Just by looking at them, it’s impossible to tell the difference between unicast and anycast addresses. Their structure is the same; it’s their functionality that’s different. The first four fields, or 64 bits, refer to the network and subnetwork. The last four fields are the interface ID, which is analogous to the host portion of the IPv4 address. Typically, the first 56 bits within the address are the routing (or global) prefix and the next 8 bits refer to the subnet ID. It’s also possible to have shorter routing prefixes though, such as 48 bits, meaning the subnet ID will be longer.
The Interface ID portion of the address can be created in one of four ways. It can be created automatically using the interface’s MAC address, procured from a DHCPv6 server, assigned randomly, or configured manually.
Multicast addresses can take different forms. All multicast addresses use the first 8 bits as the prefix.
Working with IPv6 Addresses
In IPv4, the length of the network portion of the address was determined by the subnet mask. The network address was often written in an abbreviated form, such as 169.254.0.0/16. The /16 indicates that the first 16 bits are for the network portion and corresponds to a subnet mask of 255.255.0.0. While IPv6 doesn’t use a subnet mask, the same convention for stating the network length holds true. An IPv6 network address could be written as 2001:db8:3c4d::/48. The number after the slash indicates how many bits are in the routing prefix.
Because the addresses are quite long, there are a few ways you can write them in shorthand; in the world of IPv6 it’s all about eliminating extra zeroes. For example, take the address 2001:0db8:3c4d:0012:0000:0000:1234:56ab. The first common way to shorten it is to remove all leading zeroes. So it could also be written as 2001:db8:3c4d:12:0:0:1234:56ab. The second accepted shortcut is to replace consecutive groups of zeroes with a double colon. So now the example address becomes 2001:db8:3c4d:12::1234:56ab. It’s still long, but not quite as long as the original address.
An increasingly common occurrence is a mixed IPv4-IPv6 network. As mentioned earlier, IPv6 is backward compatible. In the address space, this is accomplished by setting the first 80 bits to 0, the next 16 bits all to 1, and the final 32 bits to the IPv4 address. In IPv6 format, it looks something like ::ffff:c0a8:173. You will often see the same address written as ::ffff:192.168.1.115 to enable easy identification of the IPv4 address.
There are a few more addresses you need to be familiar with. In IPv4, the autoconfiguration (APIPA) address range was 169.254.0.0/16. IPv6 accomplishes the same task with the link-local address fe80::/10. Every IPv6-enabled interface is required to have a link-local address, and they are nonroutable. The IPv4 loopback address of 127.0.0.1 has been replaced with ::1/128 (typically written as just ::1). Global addresses (for Internet use) are 2000::/3, and multicast addresses are FF00::/8.