

i
i
i
i
i
i
i
i
22.3. Spatial Vision 583
(a) (b)
Figure 22.28. Shape-from-shading. The images in (a) and (b) appear to have different
3D shapes because of differences in the rate of change of brightness over their surfaces.
Figure 22.29. Shading can generate a strong perception of three-dimensional shape. In this
figure, the effect is stronger if you view the image from several meters away using one eye.
It becomes yet stronger if you place a piece of cardboard in front of the figure with a hole cut
out slightly smaller than the picture (see Section 22.5).
Image courtesy Albert Yonas.
(See
also Plate XIII.)
i
i
i
i
i
i
i
i
584 22. Visual Perception
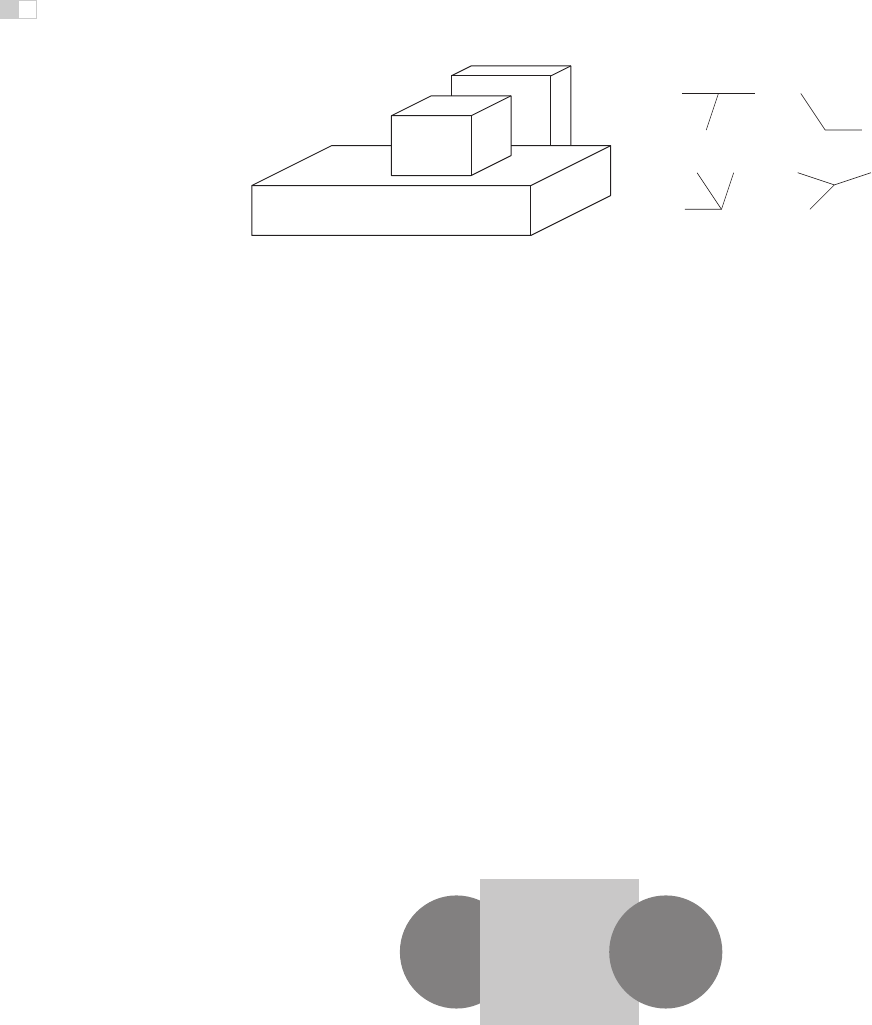
forkarrow
TL
(a) (b)
Figure 22.30. (a) Junctions provide information about occlusion and the convexity or con-
cavity of corners. (b) Common junction types for planar surface objects.
the object. Shape-from-shading is the process of recovering surface shape from
these variations in observed brightness. It is almost never possible to recover the
actual orientation of surfaces from shading alone, though shading can often be
combined with other cues to provide an effective indication of surface shape. For
surfaces with fine-scale geometric variability, shading can provide a compelling
three-dimensional appearance, even for an image rendered on a two-dimensional
surface (Figure 22.29).
There are a number of pictorial cues that yield ordinal information about
depth, without directly indicating actual distance. In line drawings, different types
of junctions provide constraints on the 3D geometry that could have generated the
drawing (Figure 22.30). Many of these effects occur in more natural images as
well. Most perceptually effective of the junction cues are T-junctions, which are
strong indicators that the surface opposite the stem of the T is occluding at least
one more distant surface. T-junctions often generate a sense of amodal comple-
tion, in which one surface is seen to continue behind a nearer, occluding surface
(Figure 22.31).
Atmospheric effects cause visual changes that can provide information about
depth, particularly outdoors over long distances. Leonardo da Vinci was the first
Figure 22.31. T-junctions cause the left disk to appear to be continuing behind the rectangle,
while the right disk appears in front of the rectangle which is seen to continue behind the disk.
i
i
i
i
i
i
i
i
22.4. Objects, Locations, and Events 585
to describe aerial perspective (also called atmospheric perspective), in which
scattering reduces the contrast of distant portions of the scene and causes them
to appear more bluish than if they were nearer (da Vinci, 1970) (see Plate XX).
Aerial perspective is predominately a relative depth cue, though there is some
speculation that it may affect perception of absolute distance as well. While many
people believe that more distant objects look blurrier due to atmospheric effects,
atmospheric scattering actually causes little blur.
22.4 Objects, Locations, and Events
While there is fairly wide agreement among current vision scientists that the pur-
pose of vision is to extract information about objects, locations, and events, there
is little consensus on the key features of what information is extracted, how it is
extracted, or how the information is used to perform tasks. Significant contro-
versies exist about the nature of object recognition and the potential interactions
between object recognition and other aspects of perception. Most of what we
know about location involves low-level spatial vision, not issues associated with
spatial relationships between complex objects or the visual processes required to
navigate in complex environments. We know a fair amount about how people
perceive their speed and heading as they move through the world, but have only
a limited understanding of actual event perception. Visual attention involves as-
pects of the perception of objects, locations, and events. While there is much data
about the phenomenology of visual attention for relatively simple and well con-
trolled stimuli, we know much less about how visual attention serves high-level
perceptual goals.
22.4.1 Object Recognition
Object recognition involves segregating an image into constituent parts corre-
sponding to distinct physical entities and determining the identity of those entities.
Figure 22.32 illustrates a few of the complexities associated with this process. We
have little difficulty recognizing that the image on the left is some sort of vehi-
cle, even though we have never before seen this particular view of a vehicle nor
do most of us typically associate vehicles with this context. The image on the
right is less easily recognizable until the page is turned upside down, indicating
an orientational preference in human object recognition.
Object recognition is thought to involve two, fairly distinct steps. The first
step organizes the visual field into groupings likely to correspond to objects and

i
i
i
i
i
i
i
i
586 22. Visual Perception
(a) (b)
Figure 22.32. The complexities of object recognition. (a) We recognize a vehicle-like object
even though we have likely never seen this particular view of a vehicle before. (b) The image
is hard to recognize based on a quick view. It becomes much easier to recognize if the book
is turned upside down.
surfaces. These grouping processes are very powerful (see Figure 22.33), though
there is little or no conscious awareness of the low-level image features that gener-
ate the grouping effect.
9
Grouping is based on the complex interaction of proxim-
ity, similarities in the brightness, color, shape, and orientation of primitive struc-
tures in the image, common motion, and a variety of more complex relationships.
The second step in object recognition is to interpret groupings as identified
objects. A computational analysis suggests that there are a number of distinctly
(a) (b)
Figure 22.33. Images are perceptually organized into groupings based on a complex set
of similarity and organizational criteria. (a) Similarity in brightness results in four horizontal
groupings. (b) Proximity resulting in three vertical groupings.
9
The most common form of visual camouflage involves adding visual textures that fool the per-
ceptual grouping processes so that the view of the world cannot be organized in a way that separates
out the object being camouflaged.

i
i
i
i
i
i
i
i
22.4. Objects, Locations, and Events 587
template
Figure 22.34. Template matching. The bright spot in the right image indicates the best
match location to the template in the left image.
Image courtesy National Archives and
Records Administration.
different ways in which an object can be identified. The perceptual data is unclear
as to which of these are actually used in human vision. Object recognition requires
that the vision system have available to it descriptions of each class of object
sufficient to discriminate each class from all others. Theories of object recognition
differ in the nature of the information describing each class and the mechanisms
used to match these descriptions to actual views of the world.
Three general types of descriptions are possible. Templates represent object
classes in terms of prototypical views of objects in each class. Figure 22.34 shows
asimpleexample.Structural descriptions represent object classes in terms of dis-
tinctive features of each class likely to be easily detected in views of the object,
along with information about the geometric relationships between the features.
Structural descriptions can either be represented in 2D or 3D. For 2D models
of objects types, there must be a separate description for each distinctly differ-
ent potential view of the object. For 3D models, two distinct forms of matching
strategies are possible. In one, the three-dimensional structure of the viewed ob-
ject is determined prior to classification using whatever spatial cues are available
and then this 3D description of the view is matched to 3D prototypes of known
objects. The other possibility is that some mechanism allows the determination
of the orientation of the yet-to-be identified object under view. This orientation
information is used to rotate and project potential 3D descriptions in a way that
allows a 2D matching of the description and the viewed object. Finally, the last
option for describing the properties of object classes involves invariant features
which describe classes of objects in terms of more generic geometric properties,
particularly those that are likely be be insensitive to different views of the object.
22.4.2 Size and Distance
In the absence of more definitive information about depth, objects which project
onto a larger area of the retina are seen as closer compared with objects which
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.