
Configure Farm Search Administration
The SharePoint Search Service is installed with its own administrative pages, which can be accessed from the Service Applications list. To open search administration, do the following:
1. From SharePoint 2010 Central Administration, under Application Management, click Manage Service Applications.
2. Click the link representing your search application, or click the row that the application is on and click the Manage button on the toolbar.
3. The Search Administration screen opens, as shown in Figure 8.7.
Figure 8.7: Search Administration screen
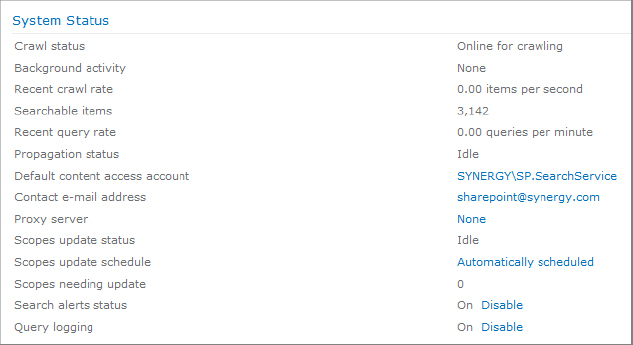
The Search Administration screen provides links to the majority of the configuration commands that are used to manage the search service. The main page lists a number of key measurements and settings. The following list describes some of the settings:
Crawl Status Indicates whether the crawler is currently online and active.
Background Activity Indicates how actively SharePoint is using resources in the background.
Recent Crawl Rate Lists the number of content crawl requests processed per second. This is a good indicator of the crawler’s performance.
Searchable Items Includes the number of items that have been crawled and indexed.
Recent Query Rate Indicates the number of search responses returned to users. This is a good indicator of the query service’s performance.
Propagation Status Indicates whether index items are currently being copied from the crawler to the query servers. Problems with propagation would be indicated here.
Default Content Access Account Specifies the domain account that is configured to index the content on the network.
Contact E-mail Address Contains an address that is passed to websites that are crawled in case the crawler causes problems during the crawl.
Proxy Server Indicates the identity of the proxy server configured to allow the crawler to access content.
Scopes Update Status Indicates whether any search scopes are currently being recalculated by the search service.
Scopes Update Schedule Indicates whether refreshing of search scopes is handled by an automated timer job or must be run manually. The default is set to Automatically Scheduled. To change to On Demand, click the link for the current setting and select the option On Demand Updates Only.
Scopes Needing Update Indicates the number of search scopes waiting to be updated.
Search Alerts Status Specifies whether search alerts are turned on.
Query Logging Indicates whether user search queries are being logged.
Configuring Farm-Level Search Settings
To access the farm-level search settings, from the Search Administration screen, click Farm Search Administration. The page is shown in Figure 8.8.
Figure 8.8: Farm Search Administration
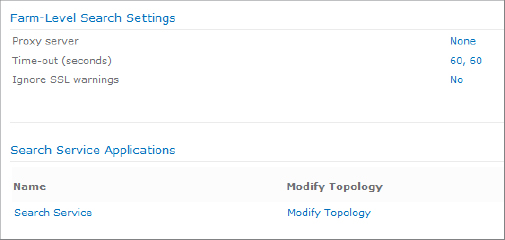
The following settings can be configured:
Proxy Server Configure this setting if the crawler needs to go through a proxy server to reach the Internet or a target network that it needs to crawl. Include the address and the port number of the server. There is an option to apply these settings to federated queries as well. Federated search queries are explained in Chapter 9, “Configuring Search Scopes and Search Results.”
Connection Time-Out Settings The default of 60 seconds is usually appropriate but may be lengthened if slow links are causing crawl failures.
Ignore SSL Certificate Name Warnings Check this option if the sites being crawled might be using a nontrusted SSL certificate such as one generated by using Microsoft Certificate Server for internal purposes.
Configuring Search Topology
The Modify Topology link in the Search Service Applications section opens the page shown in Figure 8.9, showing the current arrangement of crawler and query servers. Considerations of scalability through the use of additional components are discussed in Chapter 5, “Scaling and High Availability.”
Figure 8.9: Search Topology page
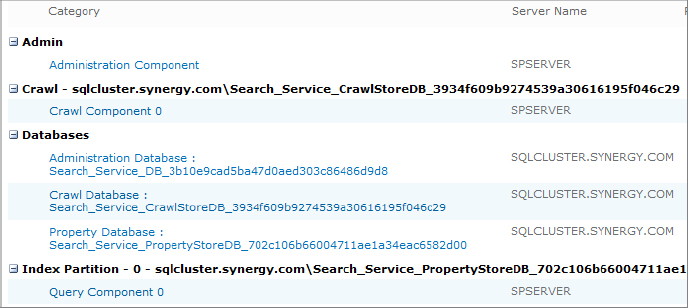
Here’s what each of the sections displayed means and how they relate to the search service:
Admin This section hosts the Administration component, which is responsible for configuring and managing the other components listed on the page. This component also initiates crawls according to the content source crawl schedules and assigns crawlers to these tasks. In addition, the database created for this component during the setup of the search service stores all the configuration details for the search topology. If the server hosting this service is offline, then changes cannot be made to the settings on the Topology screen.
Crawl This section lists components that retrieve content from the network and index it for the search service. In SharePoint 2010, the crawl component is stateless and does not hold a copy of the indexed content. Instead, it tracks which pages have been crawled and sends the index update to the query components. The crawl component also extracts metadata from the content and stores it in the designated crawl database.
Databases This section lists all the databases that are associated with the search service. The Administration database is used by the Administration component. The Crawl database is used by the Crawl component to store the record of content that has been crawled along with the date/time stamp of when it was last crawled. The Property database is used by both the Crawl and Query components to track metadata that is extracted from the indexed content.
Index Partitions Index partitions are used to divide an index into multiple segments that can be distributed to separate query servers. These divisions can reduce the size of the index and reduce the time it takes to search and retrieve results. For optimum benefit, each partition should be placed on a separate server. Index partitions can also be mirrored to separate servers so that if the primary query server fails, the server hosting the mirror can service queries.