
Splunk has several options for optimizing search performance, including summary indexing, report acceleration, and data model acceleration. We will cover both summary indexing and report acceleration later in this book. Data model acceleration helps to speed up reporting for the Object Attributes defined in a data model. This acceleration can then be leveraged by the Pivot tool when reporting.
In this recipe, you will accelerate the data models that we just created in order to familiarize yourself with the process and enhance understanding. Ordinarily, you would only really want to use data model acceleration for reporting on extremely large datasets over a period of time.
To step through this recipe, you will need a running Splunk Enterprise server, with the sample data loaded from Chapter 1, Play Time – Getting Data In, and the completed data model recipes from earlier in this chapter. You should be familiar with navigating the Splunk user interface.
Perform the following steps in this recipe to accelerate the web access and Application data models:
- Log in to your Splunk server.
- Select the Operational Intelligence application.
- Select the Settings menu item at the top-right corner of the screen, and then select Data Models.
- The two data models we created in the first two recipes will be displayed. Click on Edit next to the Application data model, and then on Edit Acceleration.

- An Add Acceleration pop-up box will be displayed, informing you that private data models cannot be accelerated. Click on the green Edit Permissions button.
- Change the Display For permissions button to App, and then click on Save.

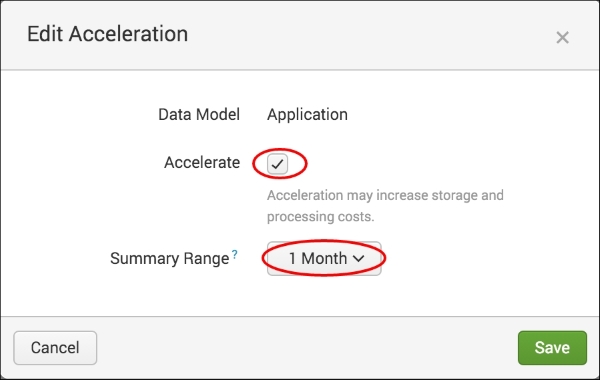
- Repeat step 4 and this time an Edit Acceleration pop-up box will appear. Check the Accelerate checkbox, select 1 Month in the Summary Range field, and then click on Save.
- In the list of Data Models, you should now see a little yellow lightning bolt, which indicates that acceleration is now activated for the Application data model.
- Repeat the previous steps to accelerate the Web Access data model. Once complete, both the models will display the yellow lightning bolt and will also have App level sharing permissions.

Once you accelerate each model, Splunk starts building acceleration summaries behind the scenes for the one month range that we selected. These summaries are built in the indexes that contain the attributes specified in each data model; in this case, the main index. The summaries are held in Splunk TSIDX files alongside the buckets of data in the index. Splunk runs an internal process to keep these summaries updated every 5 minutes and also runs a maintenance process to clean out old data every 30 minutes.
Tip
In this recipe, you accelerated both the data models. However, accelerating data models does require disk space and adds additional overhead and processing, so it is only recommended on large datasets where reporting performance is less than optimal. For more information on Splunk's data model acceleration, see http://docs.splunk.com/Documentation/Splunk/latest/Knowledge/Acceleratedatamodels.
Data model acceleration has its advantages, but it also has several caveats that you should be aware of. Some are as follows:
- Only administrators can accelerate data models and private data models cannot be accelerated.
- Acceleration adds overhead and requires disk space to build the acceleration summaries and maintain them on an ongoing basis. Therefore, acceleration is best used for large datasets where Pivot-based reporting performance is suboptimal.
- Once accelerated, the data model cannot be edited without first disabling acceleration. Disabling the acceleration, editing the data model, then re-enabling acceleration will likely require summaries to be rebuilt.
- Only root-level event objects and their direct child objects can be accelerated; the models we just accelerated fit these criteria.
- To keep data model acceleration as efficient as possible, indexes should be specified in the object constraints and the summary range limited to as short as possible. The larger the summary range, the greater the disk space and processing required.
Splunk provides some nice summary information on each data model that is not immediately apparent from the interface. From the data model management screen that lists the available data models, you will notice a small information (i) column on the far left-hand side with a greater than sign (>) next to each model. Click on this sign, and information pertaining to the data model and acceleration summaries will be displayed, including the build status of the acceleration summary and the size on disk that the summary is using. You can also force a rebuild or update of the acceleration summary.

In this recipe, you enabled acceleration through the user interface. However, behind the scenes, a number of configuration files can be edited directly to offer more flexibility.
Acceleration enablement, acceleration summary range, and the acceleration update frequency can be edited and/or configured in datamodels.conf.
The location of the data model TSIDX summaries can be changed by modifying the tstatsHomePath variable in indexes.conf.