
In this chapter, we will cover the methods that exist within Splunk to speed up intelligence. You will learn about:
- Calculating an hourly count of sessions versus completed transactions
- Backfilling the number of purchases by city
- Displaying the maximum number of concurrent sessions over time
In Chapter 5, Extending Intelligence – Data Models and Pivoting, we learned all about data models and how they can be accelerated to facilitate faster Pivot reporting. Data model acceleration works by leveraging data summarization behind the scenes. In this chapter, we will take a look at two more data summarization methods within Splunk: summary indexing and report acceleration. These enable you to speed up reports or preserve focused statistics over long periods of time. You will learn how to populate summary indexes, use report acceleration, backfill summary indexes with historical data, and more.
Data summarization
Big data is just that, big! And even with the best infrastructure, it can be extremely time-consuming to search or report over large datasets, and/or very costly to store for long periods of time. Within Splunk exist data summarization features that simplify and speed up reporting over large datasets. Data summarization essentially allows raw event datasets to be summarized to much smaller (usually statistical) datasets, which can then be searched to facilitate significantly faster reporting.
The following diagram helps to illustrate how data summarization works. In the example, we start with a large raw dataset on the left and then create a statistical summary from it, capturing the key information. The statistical summary will be much faster to report on than the raw log data as it represents a lot less data. This summarized data can either be written into a new index or be automatically captured alongside the raw event data behind the scenes by Splunk:
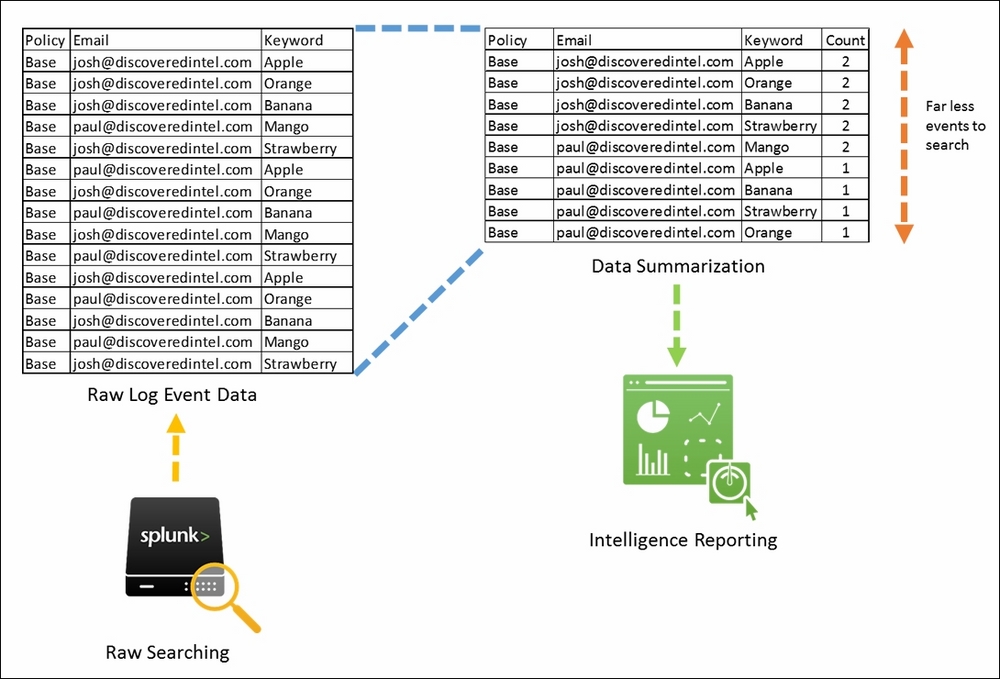
From an operational intelligence perspective, data summarization allows you to unlock the ability to quickly calculate and report on key focused metrics, while also reducing the underlying data storage footprint.
Data summarization methods
At the time of writing this book, there are three data summarization methods in Splunk, which are listed in the following table:
|
Data summarization method |
Description |
|---|---|
|
Summary indexing involves the creation of separate indexes to hold summarized event data. These indexes, instead of the index containing the raw event data, can be searched and reported on. | |
|
Report acceleration creates automated summaries behind the scenes, alongside raw event data, to facilitate faster execution of reports that have been accelerated. | |
|
Data model acceleration is similar to report acceleration in that automated summaries are created behind the scenes. However, this summarization is performed on an entire modeled set of data rather than individual reports, and the acceleration is only realized when using Pivot. |
In this chapter, we will focus on summary indexing and report acceleration, since data model acceleration was covered in Chapter 5, Extending Intelligence – Data Models and Pivoting.
About summary indexing
Summary indexing is a simple but very useful feature within Splunk that allows you to summarize large amounts of data into smaller subsets based on defined search criteria. This summarized data is usually stored in a separate index where the original data exists and is typically a lot smaller in size. Reporting over the smaller summary index rather than the original data will be a lot faster. Additionally, as the summary index is smaller, you will be able to retain data for longer periods of time, which is key for long-term trending and predictive analytics. Summary indexing is the only method to keep data for longer than the retention time of the index that stores the raw events; the other summarization methods need raw events to be present.
How summary indexing helps
One of the more common operational intelligence use cases is around the generation of metrics. For example, say we want to find the average execution time of a web request for the past month. This data might come from multiple web servers and millions of events per day. So, running a report over an entire month's raw event data will likely take a long period of time simply due to the event volume.
With summary indexing, a search can be scheduled to run each day to compute the average execution time for the day, and the results can be stored in a summary index. This will result in a summary index containing roughly 30 events for a given month—a lot less than the millions of raw event records! The following month, when this same report is run, it is merely run against the summary index that is inherently much smaller than the raw event data, resulting in a report that is computed at an exponentially faster rate than what was observed previously.
Report acceleration
When it comes to operational intelligence, detection and response times can be critical, with delays adding to costs and potential severity. Therefore, it is likely that you will want to get to your intelligence data as fast as possible. Report acceleration allows you to speed up the time it takes to execute operational intelligence reports. Report acceleration can be thought of as a form of summary indexing without the need to create a separate index, as the summary data is stored alongside ordinary indexes.
The big difference between report acceleration and summary indexing is the way in which data is computed. Summary indexing is based on the execution of scheduled searches over a given time frame that populates summary indexes with their search results. However, report acceleration is based on the execution of acceleration-enabled scheduled searches over a given time frame, which results in Splunk executing background processes to automatically manage the summary of data related to the search. In addition, report acceleration is self-repairing after any data interruption, whereas summary indexing is unaware if the data over a time frame is incomplete in any way or has endured gaps.
The ease of report acceleration
We earlier outlined that the one key difference between report acceleration and summary indexing is in the way in which report acceleration automatically handles data summarization behind the scenes. Not only is this automatically computed but Splunk also automatically identifies when searches are run, which might benefit from the already accelerated report data and make this data available to the searches; all of this is performed by one click of a button.