
- Minitab Cookbook
- Table of Contents
- Minitab Cookbook
- Credits
- About the Author
- About the Reviewers
- www.PacktPub.com
- Preface
- 1. Worksheet, Data Management, and the Calculator
- Introduction
- Opening an Excel file in Minitab
- Opening data from Access using ODBC
- Stacking several columns together
- Stacking blocks of columns at the same time
- Transposing the columns of a worksheet
- Splitting a worksheet by categorical column
- Creating a subset of data in a new worksheet
- Extracting values from a date/time column
- Calculator – basic functions
- Calculator – using an if statement
- Coding a numeric column to text values
- Cleaning up a text column with the calculator
- 2. Tables and Graphs
- Introduction
- Finding the Tally of a categorical column
- Building a table of descriptive statistics
- Creating Pareto charts
- Creating bar charts of categorical data
- Creating a bar chart with a numeric response
- Creating a scatterplot of two variables
- Generating a paneled boxplot
- Finding the mean to a 95 percent confidence on interval plots
- Using probability plots to check the distribution of two sets of data
- Creating a layout of graphs
- Creating a time series plot
- Adding a secondary axis to a time series plot
- 3. Basic Statistical Tools
- Introduction
- Producing a graphical summary of data
- Checking if data follows a normal distribution
- Comparing the population mean to a target with a 1-Sample t-test
- Using the Power and Sample Size tool for a 1-Sample t-test
- Using the Assistant menu for a 1-Sample t-test
- Looking for differences in the population means between two samples with a 2-Sample t-test
- Using the Power and Sample Size tool for a 2-Sample t-test
- Using the Assistant menu to run the 2-Sample t-test
- Finding critical t-statistics using the probability distribution plot
- Finding correlation between multiple variables
- Using the 1 Proportion test
- Graphically presenting the 1 Proportion test
- Using the Power and Sample Size tool for a 1 Proportion test
- Testing two population proportions with the 2 Proportions test
- Using the Power and Sample Size tool for a 2 Proportions test
- Using the Assistant menu to run a 2 Proportions test
- Finding the sample size to estimate a mean to a given margin of error
- Using Cross tabulation and Chi-Square
- Using equivalence tests to prove zero difference between the mean and a target
- Calculating the sample size for a 1-Sample equivalence test
- 4. Using Analysis of Variance
- Introduction
- Using a one-way ANOVA with unstacked columns
- Calculating power for the one-way ANOVA
- Using Assistant to run a one-way ANOVA
- Testing for equal variances
- Analyzing a balanced design
- Entering random effects model
- Using GLM for unbalanced designs
- Analyzing covariance
- Analyzing a fully nested design
- The repeated measures ANOVA – using a mixed effects model
- Finding the critical F-statistic
- 5. Regression and Modeling the Relationship between X and Y
- Introduction
- Visualizing simple regressions with fitted line plots
- Using the Assistant tool to run a regression
- Multiple regression with linear predictors
- Model selection tools – the best subsets regression
- Model selection tools – the stepwise regression
- Binary logistic regression
- Fitting a nonlinear regression
- 6. Understanding Process Variation with Control Charts
- Introduction
- Xbar-R charts and applying stages to a control chart
- Using an Xbar-S chart
- Using I-MR charts
- Using the Assistant tool to create control charts
- Attribute charts' P (proportion) chart
- Testing for overdispersion and Laney P' chart
- Creating a u-chart
- Testing for overdispersion and Laney U' chart
- Using CUSUM charts
- Finding small shifts with EWMA
- Control charts for rare events – T charts
- Rare event charts – G charts
- 7. Capability, Process Variation, and Specifications
- Introduction
- A capability and control chart report using the capability analysis sixpack
- Capability analysis for normally distributed data
- Capability analysis for nonnormal distributions
- Using a Box-Cox transformation for capability
- Using a Johnson transformation for capability
- Using the Assistant tool for short-run capability analysis
- Comparing the capability of two processes using the Assistant tool
- Creating an acceptance sampling plan for variable data
- Creating an acceptance sampling plan for attribute data
- Comparing a previously defined sampling plan – C = 0 plans
- Generating run charts
- Generating tolerance intervals for summarized data
- Datasets that do not transform or fit any distribution
- 8. Measurement Systems Analysis
- Introduction
- Analyzing a Type 1 Gage study
- Creating a Gage R&R worksheet
- Analyzing a crossed Gage R&R study
- Studying a nested Gage R&R
- Checking Gage linearity and bias
- Expanding a Gage study with extra factors
- Studying a go / no go measurement system
- Using the Assistant tool for Gage R&R
- Attribute Gage study from the Assistant menu
- 9. Multivariate Statistics
- Introduction
- Finding the principal components of a set of data
- Using factor analysis to identify the underlying factors
- Analyzing consistency of a test paper using item analysis
- Finding similarity in results by rows using cluster observations
- Finding similarity across columns using cluster variables
- Identifying groups in data using cluster K-means
- The discriminant analysis
- Analyzing two-way contingency tables with a simple correspondence analysis
- Studying complex contingency tables with a multiple correspondence analysis
- 10. Time Series Analysis
- 11. Macro Writing
- A. Navigating Minitab and Useful Shortcuts
- Index
Cluster variables work in a manner that is similar to cluster observations. Here, we are interested in the columns and variables in the worksheet rather than grouping the observations and rows.
We will look at the dataset for car fuel efficiency to identify groups of variables, or rather identify the columns that are similar to each other.
This dataset was collected from manufacturer-stated specifications.
- Open the
mpg.MTWworksheet. - Go to the Stat menu, click on Multivariate, and select Cluster Variables….
- Enter the columns for
CO2,Cylinders,Weight,Combined mpg,Max hp, andCapacityinto the Variables or distance matrix: section. - Check the Show dendrogram option.
- Click on OK to create the results.
- Inspect the dendrogram to identify groups in the result. The higher the value of similarity along the the y axis, the greater the similarity between columns, as shown in the following figure:
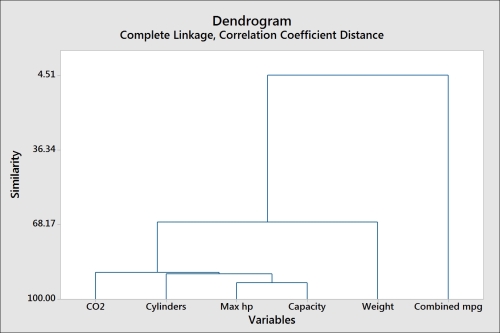
- It looks like there are three main groups of variables. Press Ctrl + E to return to the last dialog box.
- Under Number of clusters:, select 3.
- Click on OK.
As with cluster observations, we have used the single linkage method by default. We have the same options for the linkage method and distance measure as the ones used in cluster observations.
The results for the variables here show us that the combined mpg is very different when compared to the other variables.
For larger numbers of variables, dendrograms can be split into separate graphs by clusters. The Customize… option for the dendrogram can be set to the maximum number of observations per graph.
-
No Comment