
Checking conditions and alarms is the most characteristic function of any monitoring system, and Zabbix is no exception. What really sets Zabbix apart is that every alarm condition or trigger (as it is known in this system) can be tied not only to a single measurement, but also to an arbitrary complex calculation based on all of the data available to the Zabbix server. Furthermore, just as triggers are independent from items, the actions that the server can take based on the trigger status are independent from the individual trigger, as you will see in the subsequent sections.
In this chapter, you will learn the following things about triggers and actions:
- Creating complex, intelligent triggers
- Minimizing the possibility of false positives
- Setting up Zabbix to take automatic actions based on the trigger status
- Relying on escalating actions
An efficient, correct, and comprehensive alerting configuration is a key to the success of a monitoring system. It's based on extensive data collection, as discussed in Chapter 4, Collecting Data, and eventually leads to managing messages, recipients, and delivery media, as we'll see later in the chapter. But all this revolves around the conditions defined for the checks, and this is the main business of triggers.
Triggers are quite simple to create and configure—choose a name and a severity, define a simple expression using the expression form, and you are done. The expression form, accessible through the Add button, lets you choose an item, a function to perform on the item's data, and some additional parameters and gives an output as shown in the following screenshot:
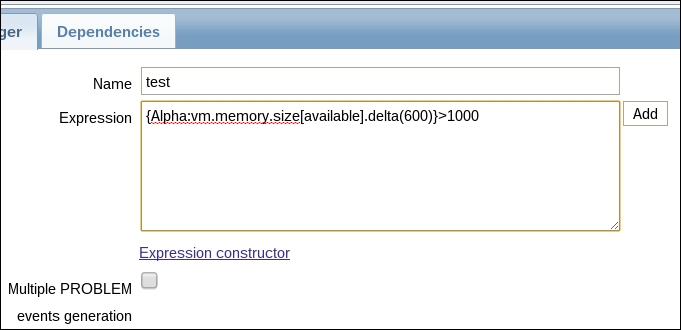
You can see how there's a complete item key specification, not just the name, to which a function is applied. The result is then compared to a constant using a greater than operator. The syntax for referencing item keys is very similar to that for a calculated item. In addition to this basic way of referring to item values, triggers also add a comparison operator that wraps all the calculations up to a Boolean expression. This is the one great unifier of all triggers; no matter how complex the expression, it must always return either a True value or a False value. This value is, of course, directly related to the state of a trigger, which can only be OK if the expression evaluates to False, or PROBLEM if the expression evaluates to True. There are no intermediate or soft states for triggers.
A trigger expression has two main components:
- Functions applied to the item data
- Arithmetical and logical operations performed on the functions' results
From a syntactical point of view, the item and function component has to be enclosed in curly brackets, as illustrated in the preceding screenshot, while the arithmetical and logical operators stay outside the brackets:
You can reference as many items as you want in a trigger expression as long as you apply a single function to every single item. This means that, if you want to use the same item twice, you'll need to specify it twice completely, as shown in the following code:
{Alpha:log[/tmp/operations.log,,,10,skip].nodata(600)}=1 or
{Alpha:log[/tmp/operations.log,,,10,skip].str(error)}=1The previously discussed trigger will evaluate to PROBLEM if there are no new lines in the operations.log file for more than 10 minutes or if an error string is found in the lines appended to that same file.
Of course, you don't have to reference items from the same host; you can reference different items from different hosts and on different proxies too (if you can access them), as shown in the following code:
{Proxy1:Alpha:agent.ping.last(0)}=0 and
{Proxy2:Beta:agent.ping.last(0)}=0Here, the trigger will evaluate to PROBLEM if both the hosts Alpha and Beta are unreachable. It doesn't matter that the two hosts are monitored by two different proxies. Everything will work as expected as long as the proxy where the trigger is defined has access to the two monitored hosts' historical data. You can apply all the same functions available for calculated items to your items' data. The complete list and specification are available on the official Zabbix wiki (https://www.zabbix.com/documentation/2.4/manual/appendix/triggers/functions), so it would be redundant to repeat them here, but a few common aspects among them deserve a closer look.
Many trigger functions take a sec or #num argument. This means that you can either specify a time period in seconds or a number of measurements, and the trigger will take all of the item's data in the said period and apply the function to it. So, the following code will take the minimum value of Alpha's CPU idle time in the last 10 minutes:
{Alpha:system.cpu.util[,idle].min(600)}The following code, unlike the previous one, will perform the same operation on the last ten measurements:
{Alpha:system.cpu.util[,idle].min(#10)}Which one should you use in your triggers? While it obviously depends on your specific needs and objectives, each one has its strengths that make it useful in the right context. For all kinds of passive checks initiated by the server, you'll often want to stick to a time period expressed as an absolute value. A #5 parameter will vary quite dramatically as a time period if you vary the check interval of the relative item. It's not usually obvious that such a change will also affect related triggers. Moreover, a time period expressed in seconds may be closer to what you really mean to check and thus may be easier to understand when you'll visit the trigger definition at a later date. On the other hand, you'll often want to opt for the #num version of the parameter for many active checks, where there's no guarantee that you will have a constant, reliable interval between measurements. This is especially true for trapper items of any kind and for log files. With these kinds of items, referencing the number of measurements is often the best option.
All the functions that return a time value, whether it's the current date, the current time, the day of the month, or the day of the week, still need a valid item as part of the expression. These can be useful to create triggers that may change their status only during certain times of the day or during certain specific days or, better yet, to define well-known exceptions to common triggers when we know that some otherwise unusual behavior is to be expected, for example, a case where there's a bug in one of your company's applications that causes a rogue process to quickly fill up a filesystem with huge log files. While the development team is working on it, they ask you to keep an eye on the said filesystem and kill the process if it's filling the disk up too quickly. As with many things in Zabbix, there's more than one way to approach this problem, but you decide to keep it simple and find that, after watching the trending data on the host's disk usage, a good indicator that the process is going rogue is that the filesystem has grown by more than 3 percent in 10 minutes:
{Alpha:vfs.fs.size[/var,pused].delta(600)}>3The only problem with this expression is that there's a completely unrelated process that makes a couple of big file transfers to this same filesystem every night at 2 a.m. While this is a perfectly normal operation, it could still make the trigger switch to a PROBLEM state and send an alert. Adding a couple of time functions will take care of that, as shown in the following code:
{Alpha:vfs.fs.size[/var,pused].delta(600)}>3 and
({Alpha:vfs.fs.size[/var,pused].time(0)}<020000 or
{Alpha:vfs.fs.size[/var,pused].time(0)}>030000 )Just keep in mind that all the trigger functions return a numerical value, including the date and time ones, so it's not really practical to express fancy dates, such as the first Tuesday of the month or last month (instead of the last 30 days).
Severity is little more than a simple label that you attach to a trigger. The web frontend will display different severity values with different colors, and you will be able to create different actions based on them, but they have no further meaning or function in the system. This means that the severity of a trigger will not change over time based on how long that trigger has been in a PROBLEM state, nor can you assign a different severity to different thresholds in the same trigger. If you really need a warning alert when a disk is over 90 percent full and a critical alert when it's 100 percent full, you will need to create two different triggers with two different thresholds and severities. This may not be the best course of action though, as it could lead to warnings that are ignored and not acted upon, critical warnings that will fire up when it's already too late and you have already lost service availability, just a redundant configuration with redundant messages and more possibilities of mistakes, or an increased signal-to-noise ratio.
A better approach would be to clearly assess the actual severity of the potential for the disk to fill up and create just one trigger with a sensible threshold and, possibly, an escalating action if you fear that the warning could get lost among the others.
If you look at many native agent items, you'll see that a lot of them can express measurements either as absolute values or as percentages. It often makes sense to do this while creating one's own custom items as both representations can be quite useful in and of themselves. When it comes to creating triggers on them, though, the two can differ quite a lot, especially if you have the task of keeping track of available disk space.
Filesystem sizes and disk usage patterns vary quite a lot between different servers, installations, application implementations, and user engagements. While a free space of 5 percent of a hypothetical disk A could be small enough that it would make sense to trigger a warning and act upon it, the same 5 percent could mean a lot more space for a large disk array, enough for you to not really need to act immediately but plan a possible expansion without any urgency. This may lead you to think that percentages are not really useful in these cases and even that you can't really put disk-space-related triggers in templates as it would be better to evaluate every single case and build triggers that are tailor-made for every particular disk with its particular usage pattern. While this can certainly be a sensible course of action for particularly sensible and critical filesystems, it can quickly become too much work in a large environment where you may need to monitor hundreds of different filesystems.
This is where the delta function can help you create triggers that are general enough that you can apply them to a wide variety of filesystems so that you can still get a sensible warning about each one of them. You will still need to create more specialized triggers for those special, critical disks, but you'd have to anyway.
While it's true that the same percentages may mean quite a different thing for disks with a great difference in size, a similar percentage variation of available space on a different disk could mean quite the same thing: the disk is filling up at a rate that can soon become a problem:
{Template_fs:vfs.fs.size[/,pfree].last(0)}<5 and
({Template_fs:vfs.fs.size[/,pfree].delta(1d)} or
{Template_fs:vfs.fs.size[/,pfree].last(0,1d) } > 0.5)The previously discussed trigger would report a PROBLEM state not just if the available space is less than 5 percent on a particular disk, but also if the available space has been reduced by more than half in the last 24 hours (don't miss the time-shift parameter in the last function). This means that no matter how big the disk is, based on its usage pattern it could quickly fill up. Note also how the trigger would need progressively smaller and smaller percentages for it to assume a PROBLEM state, so you'd automatically get more frequent and urgent notifications as the disk is filling up.
For these kinds of checks, percentage values should prove more flexible and easy to understand than absolute ones, so that's what you probably want to use as a baseline for templates. On the other hand, absolute values may be your best option if you want to create a very specific trigger for a very specific filesystem.
As you may have already realized, practically every interesting trigger expression is built as a logical operation between two or more simpler expressions. Naturally, it is not that this is the only way to create useful triggers. Many simple checks on the status of an agent.ping item can literally save the day when quickly acted upon, but Zabbix also makes it possible, and relatively easy, to define powerful checks that would require a lot of custom coding to implement in other systems. Let's see a few more examples of relatively complex triggers.
Going back to the date and time functions, let's say that you have a trigger that monitors the number of active sessions in an application and fires up an alert if that number drops too low during certain hours because you know that there should always be a few automated processes creating and using sessions in that window of time (from 10:30 to 12:30 in this example). During the rest of the day, the number of sessions is neither predictable, nor that significant, so you keep sampling it but don't want to receive any alert. A first, simple version of your trigger could look like the following code:
{Appserver:sessions.active[myapp].min(300)}<5 and
{Appserver:sessions.active[myapp].time(0)} > 103000 and
{Appserver:sessions.active[myapp].time(0) } < 123000The only problem with this trigger is that if the number of sessions drops below five in that window of time but it doesn't come up again until after 12:30, the trigger will stay in the PROBLEM state until the next day. This may be a great nuisance if you have set up multiple actions and escalations on that trigger as they would go on for a whole day no matter what you do to address the actual session's problems. But even if you don't have escalating actions, you may have to give accurate reports on these event durations, and an event that looks as if it's going on for almost 24 hours would be both incorrect in itself and for any SLA reporting. Even if you don't have reporting concerns, displaying a PROBLEM state when it's not there anymore is a kind of false positive that will not let your monitoring team focus on the real problems and, over time, may reduce their attention on that particular trigger.
A possible solution is to make the trigger return to the OK state outside the target hours if it was in a PROBLEM state, as shown in the following code:
({Appserver:sessions.active[myapp].min(300)}<5 and
{Appserver:sessions.active[myapp].time(0)} > 103000 and
{Appserver:sessions.active[myapp].time(0) } < 123000)) or
({TRIGGER.VALUE}=1 and
{Appserver:sessions.active[myapp].min(300)}<0 and
({Appserver:sessions.active[myapp].time(0)} < 103000 or
{Appserver:sessions.active[myapp].time(0) } > 123000))The first three lines are identical to the trigger defined before. This time, there is one more complex condition, as follows:
- The trigger is in a
PROBLEMstate (see the note about theTRIGGER.VALUEmacro) - The number of sessions is less than zero (this can never be true)
- We are outside the target hours (the last two lines are the opposite of those defining the time frame preceding it)
Tip
The
TRIGGER.VALUEmacro represents the current value of the trigger expressed as a number. A value of0meansOK,1meansPROBLEM, and2meansUNKNOWN. The macro can be used anywhere you can use anitem.functionpair, so you'll typically enclose it in curly brackets. As you've seen in the preceding example, it can be quite useful when you need to define different thresholds and conditions depending on the trigger's status itself.
The condition about the number of sessions being less than zero makes sure that outside the target hours, if the trigger was in a PROBLEM state, the whole expression will evaluate to false anyway. False means that the trigger is switching to the OK state.
Here, you have not only made a correlation between an item value and a window of time to generate an event, but you have also made sure that the event will always spin down gracefully instead of potentially going out of control.
Another interesting way to build a trigger is to combine different items from the same hosts or even different items from different hosts. This is often used to spot incongruities in your system state that would otherwise be very difficult to identify.
An obvious case could be that of a server that serves content over the network. Its overall performance parameters may vary a lot depending on a great number of factors, so it would be very difficult to identify sensible trigger thresholds that wouldn't generate a lot of false positives or, even worse, missed events. What may be certain though is that if you see a high CPU load while network traffic is low, then you may have a problem, as shown in the following code:
{Alpha:system.cpu.load[all,avg5].last(0)} > 5 and
{Alpha:net.if.total[eth0].avg(300)} < 1000000An even better example would be about the necessity to check for hanging or frozen sessions in an application. The actual way to do this would depend a lot on the specific implementation of the said application, but for illustrative purposes, let's say that a frontend component keeps a number of temporary session files in a specific directory, while the database component populates a table with the session data. Even if you have created items on two different hosts to keep track of these two sources of data, each number taken alone will certainly be useful for trending analysis and capacity planning, but they need to be compared to check whether something's wrong in the application's workflow. Assuming that we have previously defined a local command on the frontend's Zabbix agent that will return the number of files in a specific directory, and that we have defined an odbc item on the database host that will query the DB for the number of active sessions, we could then build a trigger that compares the two values and reports a PROBLEM state if they don't match:
{Frontend:dir.count[/var/sessions].last(0)} <>
{Database:sessions.count.last(0)}Aggregated and calculated items can also be very useful in building effective triggers. The following one will make sure that the ratio between active workers and the available servers doesn't drop too low in a grid or cluster:
{ZbxMain:grpsum["grid", "proc.num[listener]", last, 0].last(0)} /
{ZbxMain:grpsum["grid", "agent.ping", last, 0].last(0)} < 0.5All these examples should help drive home the fact that once you move beyond checking for simple thresholds with single-item values and start correlating different data sources together in order to have more sophisticated and meaningful triggers, there is virtually no end to all the possible variations of trigger expressions that you can come up with.
By identifying the right metrics, as explained in Chapter 4, Collecting Data, and combining them in various ways, you can pinpoint very specific aspects of your system behavior; you can check log files together with the login events and network activity to track down possible security breaches, compare a single server's performance with the average server performance in the same group to identify possible problems in service delivery, and do much more.
This is, in fact, one of Zabbix's best-kept secrets that really deserve more publicity; its triggering system is actually a sophisticated correlation engine that draws its power from a clear and concise method to construct expressions as well as from the availability of a vast collection of both current and historical data. Spending a bit of your time studying it in detail and coming up with interesting and useful triggers that are tailor-made for your needs will certainly pay you back tenfold as you will end up not only with a perfectly efficient and intelligent monitoring system, but also with a much deeper understanding of your environment.