
Now that we know about some of the automation features, let's take a look at a feature in Zabbix that allows us to define regular expressions in an easier—and sometimes more powerful—way. This feature can be used in low-level discovery, discussed here, and other locations.
There are quite a lot of places in Zabbix where regular expressions can be used—we already looked at icon mapping in Chapter 9, Visualizing the Data with Graphs and Maps, and log filtering in Chapter 11, Advanced Item Monitoring. In all these places, we defined the regular expression directly. But sometimes, we might want to have a single expression that we could reuse, or the expression could be overly complicated when typed in directly. For example, our filtering of loopback interfaces earlier was not the most readable thing. This is where global regular expressions can help. Let's see how we could have used this feature to simplify that filtering. Navigate to Administration | General, choose Regular expressions from the dropdown, and click on New regular expression. To see what we could potentially do here, expand the EXPRESSION TYPE dropdown:

Character string included and Character string not included both seem pretty simple. This expression would match or negate the matching of a single string. Any character string included is a bit more complicated—according to the DELIMITER dropdown (which appears when we choose Any character string), we could enter multiple values and if any of those were found, it would be a match:
For example, leaving the Delimiter dropdown at the default setting, comma, and entering ERROR, WARNING in the Expression field would match either the ERROR or WARNING string.
The two remaining options, Result is TRUE and Result is FALSE, are the powerful ones. Here, we could enter ^[0-9] in the Expression field and match when the string either starts or does not start with a number. Actually, only these last two work with regular expressions; the first three are string-matching options. They do not even offer any extra functionality besides making things a bit simpler—technically, they are not regular expressions, but are supported here for convenience.
Previously, when we wanted to filter out an interface with the name lo, we used the following regular expression for that:
^([^l].*|l[^o]|lo.+)$
It's fairly complicated. Let's create a global regular expression that would do the same. Enter Name as Exclude loopback.
In the Expressions block, fill in:
- EXPRESSION TYPE: Result is FALSE
- EXPRESSION:
^lo$
Click on the Add button at the very bottom.
But once something like that has been configured here, how would we use it in the LLD rule filter? Global regular expressions can be used in place of a normal regular expression by prefixing its name with the at (@) sign. To do so, go to Configuration | Templates, click on Discovery next to C_Template_Linux, and click on Interface discovery in the NAME column. Switch to the Filters tab, and replace the only value in the REGULAR EXPRESSION column with @Exclude loopback.
When done, click on Update. The new configuration should work exactly the same, but it seems to be much easier to understand.
Another place where global regular expressions come in handy is log monitoring. Similar to LLD rule filters, we just use an @-prefixed expression name instead of typing the regexp in directly. For example, we could define a regular expression like this:
(ERROR|WARNING) 13[0-9]{3}It would catch any errors and warnings with the error code in the 13,000 range—because that might be defined to be of concern to us. Assuming we named our global "regexp errors and warnings 13k", the log monitoring key would look like this:
log[/path/to/the/file,@errors and warnings 13k]
Let's return to Administration | General, choose Regular expressions in the dropdown, and click on New regular expression. Add three expressions here as follows:
- First expression:
- EXPRESSION TYPE: Character string included
- EXPRESSION:
A - CASE SENSITIVE:
yes
- Second expression:
- Expression type: Result is TRUE
- Expression:
^[0-9]
- Third expression:
- Expression type: Result is FALSE
- Expression:
[0-9]$
This should match a string that contains an uppercase A, starts with a number, and does not end with a number. Now, switch to the Test tab and enter 1A2 in the Test string field; then, click on Test expressions. In the following screenshot of the result area, it shows that a string starting with a number and containing an uppercase A matches, but then, the string ends with a number, which we negated. As a result, the final test fails.
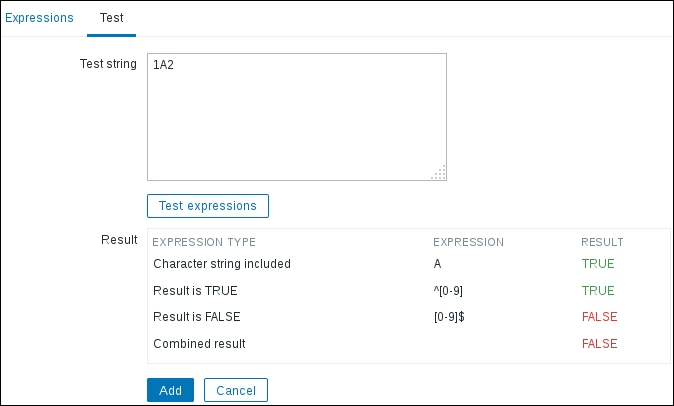
As we created our own global regexp, you probably noticed that there were a few already existing there. Let's navigate to Administration | General and choose Regular expressions in the dropdown again. Besides the one we created for the loopback interface filtering, there are three existing expressions:

One of them, Network interfaces for discovery, actually does almost the same thing as ours did, except that it also excludes interfaces whose names start with Software Loopback Interface—that's for MS Windows monitoring. The File systems for discovery one can be used to limit the types of filesystems to monitor—besides ext3, which we filtered for, it includes a whole bunch of other filesystem types. The Storage devices for SNMP discovery one excludes memory statistics from storage devices when monitoring over SNMP. While the filesystem type regexp could be typed in directly, the others would be nearly impossible—POSIX EXTENDED does not really support negating multiple strings in a reasonable way.