
SSE3 Instruction Set
Introduction
13 new instructions were introduced in the 90nm Pentium® 4 processor. They are referred to as the SSE3 instruction set. No new registers were introduced. The SSE3 instructions fall into five categories:
One new x87 FP-to-integer conversion instruction:
- the FISTTP instruction. See “Improved x87 FP-to-Integer Conversion Instruction” on page 1099.
Complex arithmetic instructions:
- the ADDSUBPS, ADDSUBPD, MOVSLDUP, MOVSHDUP, and MOVDDUP instructions. See “New Complex Arithmetic Instructions” on page 1100.
One new video encoding instruction:
- the LDDQU instruction. See “Improved Motion Estimation Performance” on page 1101.
Graphics-oriented instructions:
- the HADDPS, HSUBPS, HADDPD, and HSUBPD instructions. See “Instructions to Improve Processing of a Vertex Database” on page 1102.
Two new thread synchronization instructions:
- the MONITOR and MWAIT instructions. See “Thread Synchronization Instructions” on page 1104.
The sections that follow describe these new instructions.
Improved x87 FP-to-Integer Conversion Instruction
The Problem
When FISTP is executed to convert an x87 FP value into an integer, the processor uses the rounding algorithm specified in the FCW[RC] field. The Fortran, C and C++ specifications call for the rounding mode to be set to Chop when converting an x87 FP number to an integer, but the default rounding mode in FCW[RC] is usually set to even to minimize rounding errors. Performing the conversion therefore involves the following steps:
fstcw <old FCW> ;store current FCW in memory
movw ax,<old FCW> ;set ax = current FCW contents
or ax,0xc00 ;change RC setting to Chop
movw <new FCW>,ax ;save new FCW settings in memory
fldcw <new FCW> ;load new setting into FCW
fistp <INT> ;convert FP value to an integer
fldcw <old FCW> ;change FCW back to original
;setting
This operation caused the FCW to be changed twice (using the FLDCW instruction) and this instruction executes relatively slowly.
The Solution
The new x87 FP-to-integer conversion instruction, FISTTP, ignores FCW[RC] and always uses chop as its rounding mode. Rather than the code fragment shown in the previous section, the same conversion can be accomplished with this code fragment:
fisttp <INT> ;convert FP to integer using
;Chop RC
I think that speaks for itself. The FISTTP instruction is available in three precisions: word (16-bit), dword (32-bit), and qword (64-bit).
New Complex Arithmetic Instructions
The following new complex arithmetic instructions have been added to the instruction set (as part of the SSE3 instruction set):
ADDSUBPS and ADDSUBPD perform a mix of FP addition and subtraction, removing the need for changing the sign of some operands.
MOVSLDUP, MOVSHDUP and MOVDDUP (in their memory versions) combine loads with some level of duplication, hence saving the need for a shuffle instruction on the loaded data.
The code sequence that follows illustrates how to implement a DP complex multiplication using only SSE2 instructions:
movapd xmm0, <mem_X> movapd xmm1, <mem_Y> movapd xmm2, <mem_Y> unpcklpd xmm1, xmm1 unpckhpd xmm2, xmm2 mulpd xmm1, xmm0 mulpd xmm2, xmm0 xorpd xmm2, xmm7 shufpd xmm2, xmm2,0x1 addpd xmm2, xmm1 movapd <mem_Z>, xmm2
The code sequence that follows accomplishes the same goal using the new SSE3 instructions:
movapd xmm0, <mem_X> movddup xmm1, <mem_Y> movddup xmm2, <mem_Y+8> mulpd xmm1, xmm0 mulpd xmm2, xmm0 shufpd xmm2, xmm2,0x1 addsubpd xmm2, xmm1 movapd <mem_Z>, xmm2
The real key here is the number of μops that must be executed:
Seven μops for the SSE2 example.
Four μops for the SSE3 example.
The new complex arithmetic instructions can improve complex multiplication performance by up to 75%.
Improved Motion Estimation Performance
The Problem
A video encoder determines Motion Estimation (ME) by comparing blocks from the current video frame against blocks from the previous frame looking for the closest match. Many of the blocks from the previous frame are unaligned whereas loads of the blocks from the current frame are aligned. Unaligned loads suffer two penalties:
The performance degradation associated with handling an unaligned access.
The performance degradation associated with accesses that cross cache line boundaries.
There is not a μop capable of loading an unaligned 16-byte data object from memory. As a result, unaligned 16-byte load instructions (e.g., MOVUPS and MOVDQU) are emulated with microcode. Two 8-byte loads are executed and then merged to form the 16-byte result. Naturally, this has a performance cost and, if the access crosses a cache line boundary (a 64 byte L1 Data Cache line), there can be additional cost incurred.
The Solution
The LDDQU instruction has been added to address the cache line split problem. When executed, this instruction reads 32 bytes from memory starting on a 16-byte aligned address. This is the area that contains the requested, unaligned 16 byte block. Because it loads more bytes than requested, LDDQU should not be used in UC and WC memory areas (because locations will be read that were not requested, possibility changing the state of the device).
Motion Estimation using SSE/SSE2 instructions:
movdqa xmm0, <current> movdqu xmm1, <previous> psadbw xmm0, xmm1 paddw xmm2, xmm0
Motion Estimator using SSE3 instructions:
movdqa xmm0, <current> lddqu xmm1, <previous> psadbw xmm0, xmm1 paddw xmm2, xmm0
Intel® estimates that, assuming 25% of the unaligned loads will cross a cache line boundary, the new instruction can improve the performance of ME by up to 30%. Intel® testing indicated that MPEG 4 encoders demonstrated speedups greater than 10%.
The Downside
Use of this instruction may result in reduced performance if the application requires the performance benefit associated with Store Forwarding.
Instructions to Improve Processing of a Vertex Database
Most (graphics) vertex databases are organized as an Array of Structures (AOS), where each vertex structure contains data fields such as the following:
x, y, z, w. The coordinates of the vertex.
nx, ny, nz, nw. The coordinates of the normal at the vertex.
r, g, b, a. The colors at the vertex.
u0, v0. The first set of 2D texture coordinates.
u1, v1. The second set of 2D texture coordinates.
SSE is good at handling vertex databases organized as a Structure of Arrays (SOA), where:
The first array contains the x coordinates of all the vertices;
The second array contains the y coordinates of all the vertices;
etc.
Since the AOS approach is the norm for vertex database organization, when using SSE instructions to process database information the data must frequently be loaded from memory and then reorganized using shuffle instructions.
The scalar product operation is the most frequently performed operation in a vertex shader routine. It multiplies three or four pairs of SP FP data elements and the three or four results are then summed. The SSE3 instruction set adds horizontal FP add and subtract instructions to expedite the evaluation of scalar products. Figure 42-2 on page 1104 illustrates an example of a horizontal add or subtract operation.
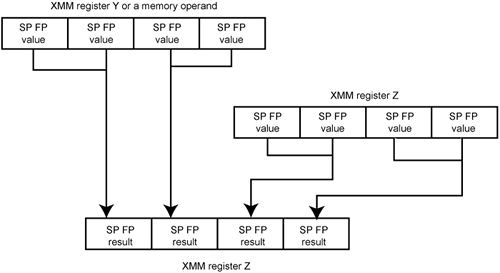
The code sequences that follow illustrate how a scalar product of four SP pairs of elements can be evaluated with and without the new instructions.
Code using SSE/SSE2 instructions:
;whole lot of shuffling going on mulps xmm0, xmm1 movaps xmm1, xmm0 shufps xmm0, xmm1, 0xb1 addps xmm0, xmm1 movaps xmm1, xmm0 shufps xmm0, xmm0, 0x0a addps xmm0, xmm1
Code using SSE3 instructions:
;no more shuffling mulps xmm0, xmm1 haddps xmm0, xmm0 haddps xmm0, xmm0
Thread Synchronization Instructions
Refer to “The MONITOR and MWAIT Instructions” on page 1110.