
The SSE2 Instruction Set
General
The 130nm Pentium® 4 processor added 144 new instructions to the IA32 instruction set. The programmer may determine whether a processor supports these instructions by executing a CPUID request type 1 and verifying that EDX[26] = 1 (see Figure 56-6).

Generally, the SSE2 instructions add the following functionality:
A new data type, 64-bit DP FP numbers, has been added.
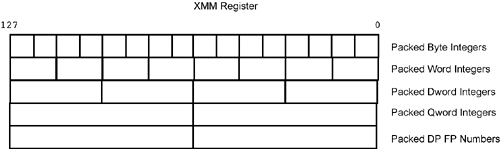
The programmer can now pack two, 64-bit DP FP numbers (see Figure 56-7 on page 1334) in each of two XMM registers and then perform packed FP operation on them (or between two numbers packed in an XMM register and two in memory).
New instructions have been added to perform scalar operations (see “Scalar Operations” on page 772) on 64-bit DP FP numbers in the XMM registers.
The MMX and SSE instructions have been enhanced to perform operations on data items packed in the XMM registers (see Figure 56-7 on page 1334).
The CLFLUSH, MFENCE, LFENCE and new streaming store instructions have been added.
DP FP Number Representation
A primer on the representation of 32-bit SP FP numbers was covered in “The 32-bit SP FP Numeric Format” on page 761. In the DP FP format, like the 32-bit SP FP format, the digit to the left of the decimal point is assumed to be one. With wider significand (also referred to as the mantissa) and biased-exponent fields, a wider range of values can be represented (2.23 x 10-308 to 1.79 x 10308, versus 1.18 x 10–38 to 3.40 x 1038 for SP FP numbers).
Figure 56-8. 64-bit DP FP Numeric Format

Packed and Scalar DP FP Instructions
The SSE2 instructions that can perform operations on packed and scalar DP FP numbers are divided into the following groups:
The data movement instructions.
The arithmetic instructions.
The compare instructions.
The data type conversion instructions.
The logical instructions.
The shuffle instructions.
SSE2 64-Bit and 128-Bit SIMD Integer Instructions
The SSE2 instructions that can perform SIMD operations on packed integers are:
the MOVDQA (move aligned double qword) instruction.
the MOVDQU (move unaligned double qword) instruction.
the PADDQ (packed qword add) instruction.
the PSUBQ (packed qword subtract) instruction.
the PMULUDQ (multiply packed unsigned dword integers) instruction.
the PSHUFLW (shuffle packed low words) instruction.
the PSHUFHW (shuffle packed high words) instruction.
the PSHUFD (shuffle packed dword integers) instruction.
the PSLLDQ (shift double qword left logical) instruction.
the PSRLDQ (shift double qword right logical) instruction.
the PUNPCKHQDQ (Unpack high qwords) instruction.
the PUNPCKLQDQ (Unpack low qwords) instruction.
the MOVQ2DQ (move qword integer from MMX to XMM registers) instruction.
the MOVDQ2Q (move qword integer from XMM to MMX registers) instruction.
SSE2 128-Bit SIMD Integer Instruction Extensions
All of the 64-bit MMX and SSE SIMD integer instructions (with the exception of PSHUFW) have been extended to operate on 128-bit packed integer operands in XMM registers. The new 128-bit versions of these instructions follow the same SIMD conventions regarding packed operands as the original 64-bit versions.
As an example, where the 64-bit version of PADDB operates on eight bytes packed into an MMX register, the 128-bit version has been extended to operate on 16 bytes packed into an XMM register.
Your Choice: Accuracy or Speed
The Pentium® III processor added the SSE instruction set, the XMM registers, and the MXCSR register. As previously described in “Accuracy vs. Fast Real-Time 3D Processing” on page 765, the MXCSR register's FTZ (Flush-To-Zero) bit permitted the programmer a choice between an accurate result or processing speed. The Pentium® 4 processor added the DAZ (Denormals Are Zeros) bit to the MXCSR register (see Figure 56-9 on page 1337) for much the same reason.

The IEEE specification defines the range of possible real numbers as falling into the following categories (ranging from most positive to most negative):
+ ∞
+1.n, where n is > 0 (referred to as positive normal numbers)
+0.n, where n is > 0 (referred to as positive denormal numbers)
+0
-0
-0.n, where n is > 0 (referred to as negative denormal numbers)
-1.n, where n is > 0 (referred to as negative normal numbers)
- ∞
When the DAZ bit is set to one, the processor converts all denormal source operands to a zero with the sign of the original operand before performing any computations on them. The processor does not set the Denormal Operand Exception (DE) status bit to one, regardless of the setting of the Denormal Operand mask bit (DM), and does not generate a Denormal Operand exception if the exception is unmasked.
It should be stressed that DAZ mode is not compatible with IEEE Standard 754. In many streaming media applications, rounding a denormal operand to zero does not appreciably affect the quality of the processed data and the performance of the application is increased because exceptions are not generate when a denormal source operand is involved in a FP operation.
The DAZ bit affects the execution of both SSE and SSE2 FP operations.
The DAZ bit is cleared upon a power-up or reset of the processor, disabling DAZ Mode.
In all models of the Pentium® III and in some models of the Pentium® 4 processor (the author is not aware of which Pentium® 4 models), MXCSR[DAZ] is reserved. Setting MXCSR[DAZ] = 1 on a processor that doesn't support DAZ mode results in a GP exception. See “The MXCSR Mask Field” on page 716 for additional information.